
AI data readiness evaluates whether your organization’s data meets the specific quality, quantity, and governance requirements needed for successful artificial intelligence implementation. Unlike traditional data analytics, AI systems demand higher standards for data accuracy, completeness, and consistency to train reliable models and make accurate predictions. Organizations that assess data readiness before AI projects significantly reduce the risk of project failure and avoid costly mid-project corrections.
Key Takeaways
- Unstandardized processes create data quality issues that directly impact AI model performance and prediction accuracy
- Data must meet specific quality thresholds including accuracy, completeness, and consistency before AI implementation to avoid bias and performance problems
- Missing, incorrect, fragmented, or ownerless data introduces significant business risks including biased models and poor decision-making
- Auditing process and data flow before AI projects helps identify bottlenecks, governance gaps, and integration challenges
- Priority actions should focus on data inventory, governance setup, and process standardization with clear timelines
What is AI Data Readiness?
AI data readiness refers to the state of your organization’s data infrastructure and quality in relation to the specific requirements of artificial intelligence systems. While traditional analytics can work with imperfect data to some degree, AI models—particularly machine learning systems—require higher standards of data quality, structure, and governance. Data readiness encompasses not just the technical aspects of data storage and processing, but also the organizational practices around data collection, maintenance, and governance that ensure data remains reliable and accessible for AI applications.
The difference between general data quality and AI-specific data readiness lies in the scale and complexity of requirements. AI systems typically need larger volumes of data, more diverse data types, and stricter consistency standards than traditional analytics. They also require data to be properly labeled, documented, and governed to ensure model training produces reliable results. Organizations that skip data readiness assessment often discover these requirements mid-project, leading to delays, increased costs, and sometimes complete project failure. Understanding the broader AI Readiness Framework can help organizations assess their overall preparedness beyond just data.
How Unstandardized Processes Impact AI
The connection between process standardization and AI performance is direct and significant. When business processes lack standardization, the data generated from those processes becomes inconsistent, making it difficult for AI systems to learn reliable patterns. Process variability introduces noise into training data, which can lead to models that perform poorly or make inconsistent predictions. For example, if different teams follow different procedures for customer data entry, the resulting dataset will have inconsistent formats, missing values, and varying quality—all of which degrade AI model performance.
Unstandardized data pipelines create additional challenges. When data flows through multiple systems without consistent transformation rules, the same data point may have different values at different stages, creating confusion for AI systems. This is particularly problematic for machine learning models that rely on consistent feature engineering. Organizations with unstandardized processes often spend excessive time cleaning and normalizing data—time that could be better spent on model development and optimization. The cost of unstandardized data pipelines extends beyond technical effort to include business impact, as decisions based on inconsistent data may lead to poor outcomes.
Process variability also affects the ability to maintain AI systems over time. If the processes that generate training data change without proper documentation and version control, the AI models trained on that data may become less accurate or even obsolete. This is why process standardization is not just a data quality issue but a fundamental requirement for sustainable AI implementation. Organizations that address process standardization before AI projects create a more stable foundation for long-term AI success.
Data Quality Requirements for AI
Accuracy, Completeness, and Consistency
AI systems require data that is accurate, complete, and consistent across all sources. Accuracy means the data correctly represents real-world values without systematic errors or biases. Completeness ensures that critical attributes are present for all relevant records—missing values can significantly impact model training and prediction accuracy. Consistency requires that data follows the same formats, definitions, and standards across different systems and time periods. Inconsistent data creates confusion for AI systems and can lead to models that learn incorrect patterns.
The threshold for acceptable data quality varies by use case, but general best practices suggest aiming for at least 95% accuracy in critical fields, less than 5% missing values for key attributes, and 100% consistency in data definitions. Organizations should establish data quality baselines before AI projects and implement monitoring to maintain these standards throughout the AI lifecycle. Data quality issues that seem minor in traditional analytics can become major problems in AI systems due to the scale and complexity of model training. Professional data analytics services can help organizations assess and improve their data quality before AI implementation.
Data Volume and Variety Needs
AI systems typically require larger volumes of data than traditional analytics to achieve reliable performance. The exact volume depends on the complexity of the problem and the type of AI approach, but machine learning models often need thousands or millions of data points to generalize effectively. Small datasets can lead to overfitting, where models perform well on training data but poorly on new data. Organizations should assess whether they have sufficient historical data or can generate synthetic data to meet volume requirements.
Data variety is equally important. AI systems benefit from diverse data sources that capture different aspects of the problem domain. This might include structured data from databases, unstructured text from documents, images, audio, or sensor data depending on the application. The ability to integrate and process diverse data types is a key differentiator for successful AI implementations. Organizations should inventory their data sources and assess whether they provide sufficient variety to train robust models.
Labeling and Annotation Requirements
Supervised machine learning approaches require labeled data—data where the correct output or classification is known. Data labeling and annotation can be time-consuming and expensive, particularly for complex tasks like image recognition or natural language processing. Organizations must assess whether they have existing labeled data, the resources to label new data, or the ability to use semi-supervised or unsupervised approaches that require less labeling.
The quality of labels is as important as the quality of the data itself. Inconsistent or incorrect labels will train models to make wrong predictions. Organizations should establish clear labeling guidelines, train labelers on these guidelines, and implement quality control processes to ensure label accuracy. For high-stakes applications, multiple independent labelers may be needed to ensure consensus and reduce bias.
Data Freshness and Timeliness
AI systems need current data to remain relevant and accurate. Data freshness requirements vary by application—some use cases can work with slightly stale data, while others require real-time or near-real-time updates. Organizations should assess their data update frequency and determine whether it meets the needs of their AI applications. For time-sensitive applications like fraud detection or predictive maintenance, data freshness is critical and may require investment in real-time data pipelines.
Data timeliness also refers to the ability to access data when needed. If data is available but difficult to access due to system constraints, permissions, or technical limitations, it effectively doesn’t exist for AI purposes. Organizations should evaluate data accessibility and latency to ensure AI systems can get the data they need when they need it.

Risks of Poor Data Quality
Missing Data Risks
Missing data introduces several risks for AI systems. When critical attributes are missing, models may learn incorrect patterns or make biased predictions. For example, if customer demographic data is missing for certain segments, a model trained on that data may perform poorly for those segments. Missing data can also lead to overfitting if the model learns to rely on patterns that only exist in the complete records, reducing its ability to generalize.
The business impact of missing data includes poor decision-making, reduced model accuracy, and potential bias against underrepresented groups. Organizations that don’t address missing data before AI implementation may discover these issues only after models are deployed, requiring costly retraining and potentially damaging business relationships or reputation.
Incorrect Data Risks
Incorrect data—data that contains errors, inaccuracies, or inconsistencies—poses severe risks for AI systems. Models trained on incorrect data will learn incorrect patterns, leading to systematically wrong predictions. This is particularly dangerous in high-stakes applications like healthcare, finance, or safety-critical systems where incorrect predictions can have serious consequences.
The impact of incorrect data extends beyond model performance to business trust. If stakeholders discover that AI systems are making decisions based on incorrect data, they may lose confidence in the entire AI initiative. Organizations should implement data validation processes, error detection mechanisms, and regular audits to identify and correct incorrect data before it affects AI systems.
Fragmented Data Risks
Fragmented data—data that exists in silos across different systems without integration—limits the ability of AI systems to learn comprehensive patterns. When data is fragmented, AI models only see partial pictures of the problem domain, leading to incomplete insights and suboptimal decisions. Fragmentation also makes it difficult to maintain data consistency and governance across the organization.
The business risks of fragmented data include missed opportunities for cross-functional insights, inconsistent decision-making across departments, and increased complexity in data management. Organizations should assess their data landscape and identify integration opportunities before AI projects to ensure models have access to comprehensive, unified data.
Ownerless Data Risks
Ownerless data—data without clear ownership or accountability—creates maintenance and governance problems. When no one is responsible for data quality, accuracy, and updates, data tends to degrade over time. This degradation can significantly impact AI model performance, particularly for models that require ongoing training with fresh data.
Ownerless data also creates governance challenges. Without clear ownership, it’s difficult to establish data access policies, security controls, and compliance measures. Organizations should assign data owners for critical datasets and establish clear responsibilities for data maintenance, quality monitoring, and governance. This ownership structure is essential for sustainable AI operations.
How to Audit Process and Data Flow
Process Audit Framework
Auditing business processes before AI implementation helps identify variability, bottlenecks, and opportunities for standardization. The process audit framework should map current workflows, document decision points, and assess process variations across different teams or locations. This mapping reveals where processes are consistent and where they differ, providing insight into potential data quality issues.
The audit should also evaluate automation opportunities. Processes that are highly standardized and rule-based are good candidates for AI augmentation, while highly variable processes may require standardization before AI can be applied effectively. Organizations should document current process performance metrics to establish baselines for measuring AI impact later.
Data Flow Audit
Data flow auditing traces how data moves through systems from creation to consumption. This audit should identify data sources, transformation steps, storage locations, and access patterns. The goal is to understand the complete data lifecycle and identify points where data quality might degrade or where bottlenecks occur.
Key aspects of data flow auditing include mapping data lineage (the path data takes from source to destination), identifying data transformation rules, and assessing data integrity at each stage. The audit should also evaluate data access controls and security measures to ensure that AI systems will have appropriate access to needed data while maintaining compliance with privacy and security requirements. The NIST AI Risk Management Framework provides guidance on data governance and security practices for AI systems.
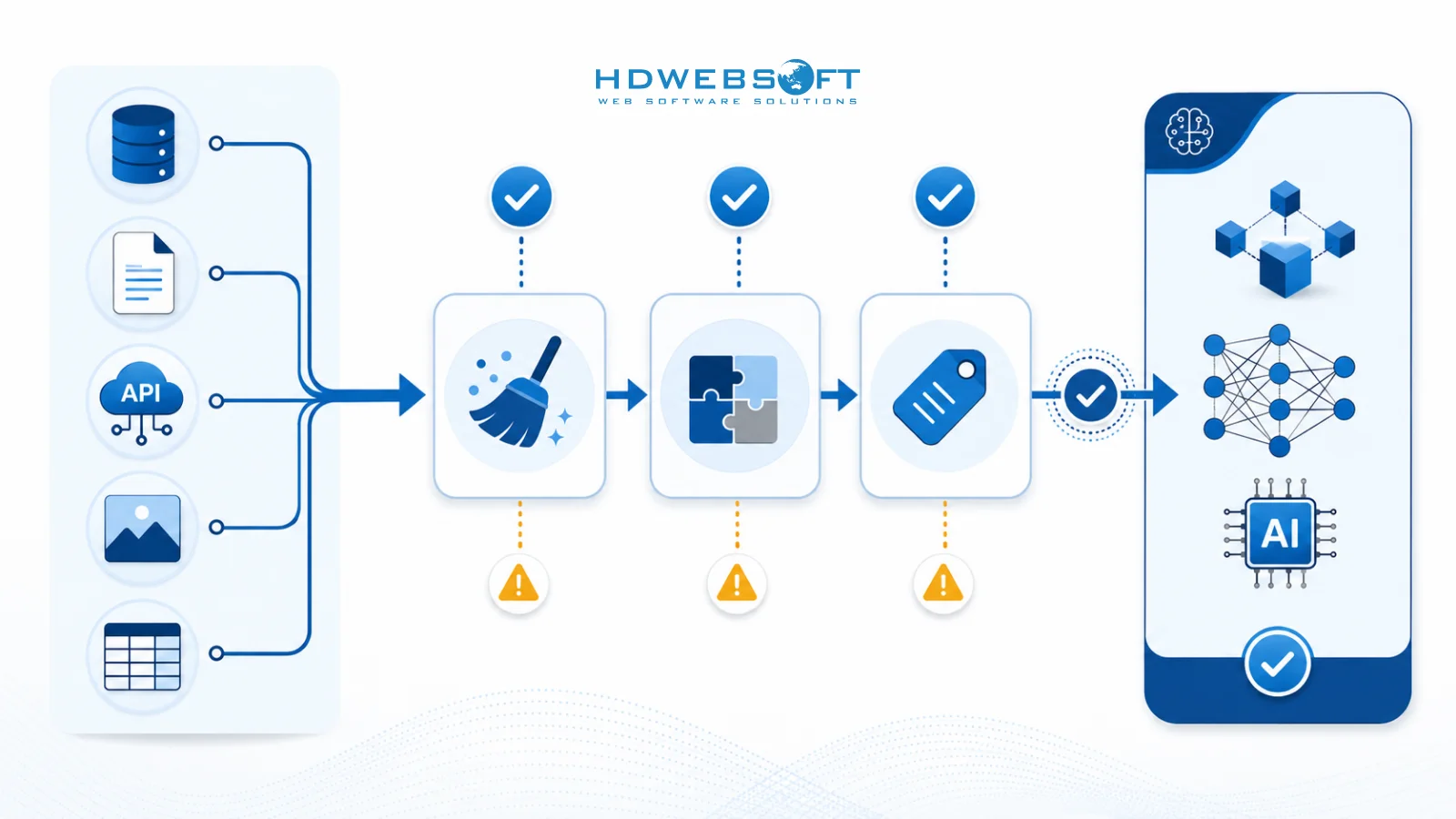
Audit Checklist
A comprehensive data readiness audit should include the following steps:
- Data Inventory: Catalog all data sources, types, volumes, and locations
- Quality Assessment: Evaluate accuracy, completeness, consistency, and freshness
- Process Mapping: Document business processes that generate or use data
- Flow Analysis: Trace data movement through systems and transformations
- Governance Review: Assess data ownership, access controls, and compliance
- Gap Identification: Compare current state against AI requirements
- Risk Assessment: Identify potential data-related risks for AI projects
- Recommendation Development: Propose specific actions to address gaps and risks
Organizations should use this checklist as a structured approach to data readiness assessment, ensuring comprehensive coverage of all critical aspects.
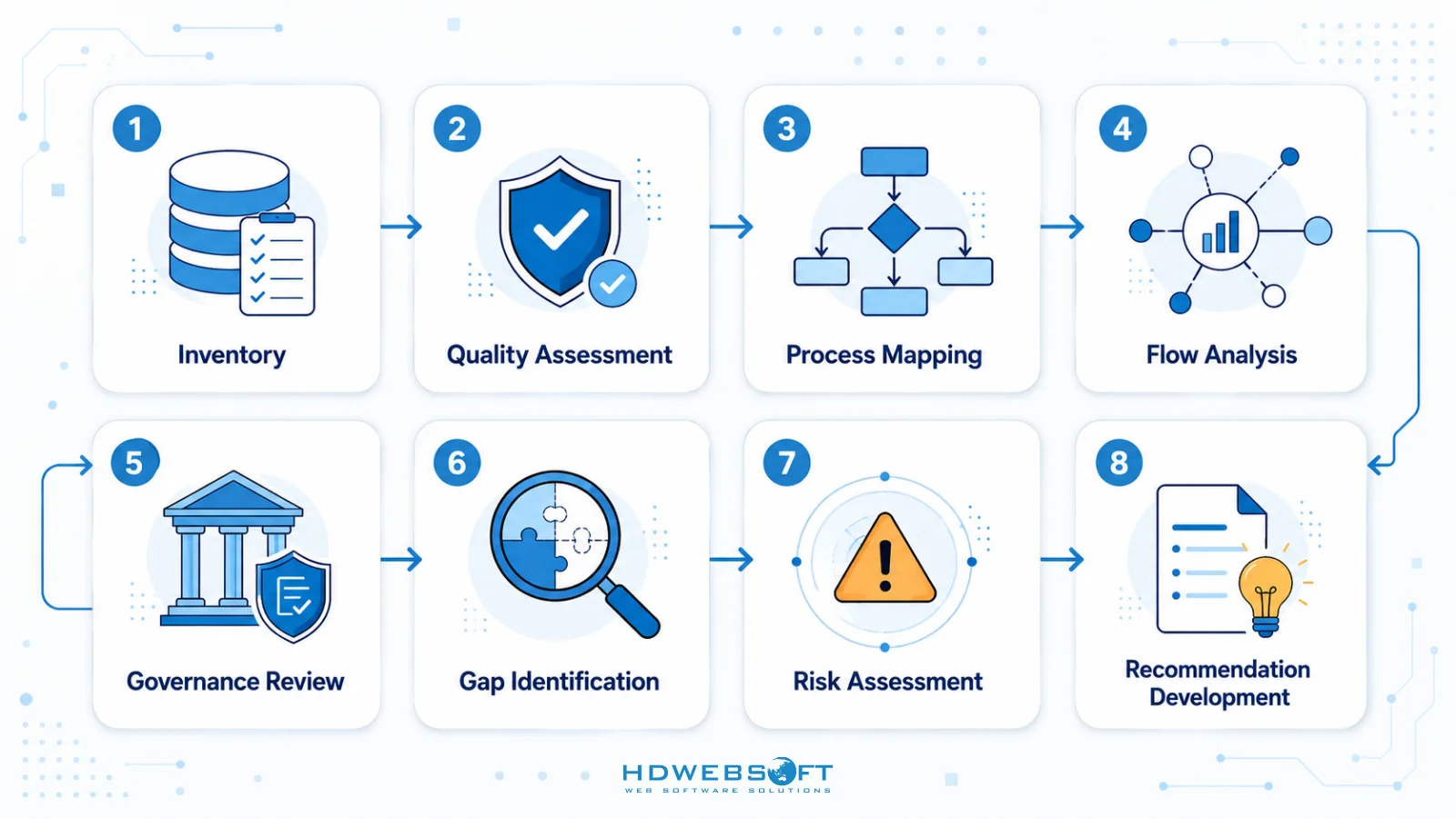
Priority Actions to Prepare Data and Workflow
Immediate Actions (Week 1-2)
The first two weeks should focus on foundational activities that provide quick wins and establish baselines. Start with a comprehensive data inventory to understand what data exists, where it’s stored, and who owns it. This inventory should include data sources, volumes, formats, and quality assessments. Simultaneously, identify the most critical data sources for your planned AI initiatives and prioritize them for immediate attention.
Establish data quality baselines by measuring current accuracy, completeness, and consistency levels. These baselines will help you measure improvement over time and set realistic expectations for AI project timelines. Begin documenting key business processes that generate or use critical data, focusing on areas with high variability or known quality issues.
Short-term Actions (Month 1-2)
The first two months should address the most critical gaps identified in the audit. Implement data cleaning and standardization for priority data sources, focusing on accuracy, completeness, and consistency. Establish a basic data governance framework by assigning data owners, defining access policies, and documenting data standards.
Begin process standardization initiatives for workflows that generate critical data. This might involve creating standard operating procedures, implementing validation rules, or training teams on consistent practices. Set up automated data quality monitoring where possible to catch issues early and maintain the improvements you’ve made.
Medium-term Actions (Month 3-6)
The medium-term focus should be on building sustainable capabilities and scaling improvements. Implement automated data quality monitoring across all critical data sources, with alerts for quality degradation. Optimize data pipelines to reduce manual effort and improve reliability. This might involve investing in data integration tools, implementing master data management, or developing automated cleaning and validation processes.
Implement process automation where standardization has been achieved, using tools like robotic process automation (RPA) or workflow automation to reduce human error and improve consistency. Establish continuous improvement processes to regularly review data quality metrics, process performance, and AI model outputs, making adjustments as needed. This creates a feedback loop that ensures data readiness improves over time rather than degrading.
AI Data Readiness Checklist
Use this checklist to assess your organization’s data readiness before AI implementation:
Data Inventory
- All critical data sources identified and cataloged
- Data volumes and varieties assessed against AI requirements
- Data owners assigned for all critical datasets
- Data access patterns documented
Data Quality
- Accuracy measured and meets minimum thresholds (95% or higher for critical fields)
- Completeness assessed with less than 5% missing values for key attributes
- Consistency verified across systems and time periods
- Data freshness requirements defined and met
Process Standardization
- Key business processes documented
- Process variability assessed and quantified
- Standard operating procedures created
- Automation opportunities identified
Data Governance
- Data governance framework established
- Access controls and security policies implemented
- Data quality monitoring in place
- Compliance requirements addressed
Technical Readiness
- Data infrastructure assessed for AI workloads
- Integration capabilities with existing systems verified
- Data pipeline architecture designed
- Scalability considerations addressed
Common Data Readiness Mistakes
Organizations often underestimate the time and effort required for data preparation, assuming it’s a quick step before the “real work” of AI development. In reality, data preparation typically consumes 60-80% of the time in AI projects. According to industry research, skipping thorough data assessment to save time usually results in longer overall timelines as issues are discovered mid-project.
Another common mistake is neglecting data lineage documentation. Without clear documentation of where data comes from, how it’s transformed, and what assumptions are built into it, organizations struggle to troubleshoot issues, reproduce results, or maintain models over time. Data lineage is essential for transparency, debugging, and regulatory compliance.
Ignoring process variability is also a frequent error. Organizations assume their processes are more consistent than they actually are, leading to unexpected data quality issues. Process standardization should be addressed early, as it’s often more difficult to fix than technical data issues.
Finally, many organizations overlook the importance of data owner assignment. Without clear ownership, data quality degrades over time, and no one is accountable for maintaining the standards needed for AI success. Assigning data owners and establishing clear responsibilities is a foundational step that should not be skipped.
Conclusion
AI data readiness is not optional—it’s a prerequisite for successful AI implementation. Organizations that invest time in assessing and improving their data readiness before AI projects significantly reduce the risk of failure and improve the likelihood of achieving meaningful business value. The investment in data preparation pays dividends through faster development cycles, more accurate models, and sustainable AI operations.
The journey to data readiness requires attention to both technical and organizational aspects. Technical improvements like data cleaning, integration, and infrastructure are necessary but not sufficient. Organizational changes like process standardization, governance frameworks, and data owner assignment are equally important for long-term success.
If you’re planning AI initiatives, start with a comprehensive data readiness assessment. HDWEBSOFT can help you evaluate your current data landscape, identify gaps, and develop a roadmap to prepare your data for AI success. Our AI development services include data assessment, governance implementation, and pipeline development to ensure your AI initiatives have the solid foundation they need.
FAQ
What is the difference between general data quality and AI data readiness?
General data quality focuses on whether data is accurate and usable for traditional analytics and reporting. AI data readiness requires higher standards—larger volumes, more diverse types, stricter consistency, and proper labeling for machine learning. AI systems also need data governance, lineage documentation, and ongoing quality monitoring that may not be required for basic analytics.
How long does it take to prepare data for AI implementation?
The timeline varies based on the current state of your data and the complexity of your AI requirements. Simple use cases with good existing data might need 4-6 weeks of preparation. Complex projects with significant data quality issues or integration challenges may require 3-6 months. Organizations should factor data preparation time into their AI project planning rather than treating it as an afterthought.
What are the most common data readiness mistakes organizations make?
The most common mistakes include underestimating data preparation time, skipping data lineage documentation, ignoring process variability, neglecting data owner assignment, and assuming existing data quality is sufficient for AI. These mistakes typically lead to project delays, increased costs, and sometimes complete project failure.
Can AI work with imperfect data, or is perfect data required?
AI can work with imperfect data, but the degree of imperfection matters. Small amounts of missing or noisy data can often be handled through data cleaning techniques and robust model design. However, significant data quality issues will impact model performance and may make AI impractical. The goal is not perfect data but data that meets minimum quality thresholds for your specific use case.
How do I know if my organization is data-ready for AI?
Your organization is data-ready for AI if you have sufficient volumes of relevant data that meets quality thresholds (accuracy, completeness, consistency), clear data ownership and governance, standardized processes that generate consistent data, and the technical infrastructure to support AI workloads. A formal data readiness assessment can help you evaluate these criteria systematically and identify any gaps that need to be addressed.
