
La preparación de datos IA evalúa si los datos de su organización cumplen con los requisitos específicos de calidad, cantidad y gobernanza necesarios para una implementación exitosa de la inteligencia artificial. A diferencia del análisis de datos tradicional, los sistemas de IA exigen estándares más altos para la precisión, integridad y consistencia de los datos para entrenar modelos confiables y hacer predicciones precisas. Las organizaciones que evalúan la preparación de datos antes de los proyectos de IA reducen significativamente el riesgo de falla del proyecto y evitan correcciones costosas a mitad del proyecto.
Puntos Clave
- Los procesos no estandarizados crean problemas de calidad de datos que impactan directamente el rendimiento del modelo de IA y la precisión de predicción
- Los datos deben cumplir con umbrales de calidad específicos que incluyen precisión, integridad y consistencia antes de la implementación de IA para evitar sesgos y problemas de rendimiento
- Los datos faltantes, incorrectos, fragmentados o sin propietario introducen riesgos comerciales significativos que incluyen modelos sesgados y una mala toma de decisiones
- El proceso de auditoría y el flujo de datos antes de los proyectos de IA ayudan a identificar cuellos de botella, brechas de gobernanza y desafíos de integración
- Las acciones prioritarias deben centrarse en el inventario de datos, configuración de gobernanza y estandarización de procesos con plazos claros
¿Qué es la Preparación de Datos IA?
La preparación de datos IA se refiere al estado de la infraestructura de datos y la calidad de su organización en relación con los requisitos específicos de los sistemas de inteligencia artificial. Mientras que el análisis tradicional puede funcionar con datos imperfectos hasta cierto punto, los modelos de IA—particularmente los sistemas de aprendizaje automático—requieren estándares más altos de calidad, estructura y gobernanza de datos. La preparación de datos abarca no solo los aspectos técnicos del almacenamiento y procesamiento de datos, sino también las prácticas organizacionales alrededor de la recopilación, mantenimiento y gobernanza de datos que aseguran que los datos permanezcan confiables y accesibles para las aplicaciones de IA.
La diferencia entre la calidad de datos general y la preparación de datos específica para IA radica en la escala y complejidad de los requisitos. Los sistemas de IA típicamente necesitan volúmenes más grandes de datos, tipos de datos más diversos y estándares de consistencia más estrictos que el análisis tradicional. También requieren que los datos estén debidamente etiquetados, documentados y gobernados para asegurar que el entrenamiento del modelo produzca resultados confiables. Las organizaciones que omiten la evaluación de preparación de datos a menudo descubren estos requisitos a mitad del proyecto, lo que lleva a retrasos, costos aumentados y, a veces, falla completa del proyecto.
Comprender el marco de preparación de IA más amplio puede ayudar a las organizaciones a evaluar su preparación general más allá de solo los datos.
Cómo los Procesos No Estandarizados Impactan la IA
La conexión entre la estandarización de procesos y el rendimiento de IA es directa y significativa. Cuando los procesos comerciales carecen de estandarización, los datos generados por esos procesos se vuelven inconsistentes, lo que dificulta que los sistemas de IA aprendan patrones confiables. La variabilidad del proceso introduce ruido en los datos de entrenamiento, lo que puede llevar a modelos que funcionan mal o hacen predicciones inconsistentes. Por ejemplo, si diferentes equipos siguen diferentes procedimientos para la entrada de datos de clientes, el conjunto de datos resultante tendrá formatos inconsistentes, valores faltantes y calidad variable—todo lo cual degrada el rendimiento del modelo de IA.
Las canalizaciones de datos no estandarizadas crean desafíos adicionales. Cuando los datos fluyen a través de múltiples sistemas sin reglas de transformación consistentes, el mismo punto de datos puede tener diferentes valores en diferentes etapas, creando confusión para los sistemas de IA. Esto es particularmente problemático para los modelos de aprendizaje automático que dependen de la ingeniería de características consistente. Las organizaciones con procesos no estandarizados a menudo pasan tiempo excesivo limpiando y normalizando datos—tiempo que podría mejor gastarse en el desarrollo y optimización de modelos. El costo de las canalizaciones de datos no estandarizadas se extiende más allá del esfuerzo técnico para incluir el impacto comercial, ya que las decisiones basadas en datos inconsistentes pueden llevar a malos resultados.
La variabilidad del proceso también afecta la capacidad de mantener los sistemas de IA con el tiempo. Si los procesos que generan los datos de entrenamiento cambian sin la documentación y control de versiones apropiados, los modelos de IA entrenados en esos datos pueden volverse menos precisos o incluso obsoletos. Es por eso que la estandarización de procesos no es solo un problema de calidad de datos sino un requisito fundamental para una implementación de IA sostenible. Las organizaciones que abordan la estandarización de procesos antes de los proyectos de IA crean una base más estable para el éxito a largo plazo de IA.
Requisitos de Calidad de Datos para IA
Precisión, Integridad y Consistencia
Los sistemas de IA requieren datos que sean precisos, completos y consistentes en todas las fuentes. La precisión significa que los datos representan correctamente los valores del mundo real sin errores sistemáticos o sesgos. La integridad asegura que los atributos críticos estén presentes para todos los registros relevantes—los valores faltantes pueden impactar significativamente el entrenamiento del modelo y la precisión de predicción. La consistencia requiere que los datos sigan los mismos formatos, definiciones y estándares en diferentes sistemas y períodos de tiempo. Los datos inconsistentes crean confusión para los sistemas de IA y pueden llevar a modelos que aprenden patrones incorrectos.
El umbral para la calidad de datos aceptable varía según el caso de uso, pero las mejores prácticas generales sugieren apuntar a al menos 95% de precisión en campos críticos, menos de 5% de valores faltantes para atributos clave y 100% de consistencia en definiciones de datos. Las organizaciones deberían establecer líneas base de calidad de datos antes de los proyectos de IA e implementar monitoreo para mantener estos estándares a lo largo del ciclo de vida de IA. Los problemas de calidad de datos que parecen menores en el análisis tradicional pueden convertirse en problemas mayores en los sistemas de IA debido a la escala y complejidad del entrenamiento del modelo.
Los servicios profesionales de análisis de datos pueden ayudar a las organizaciones a evaluar y mejorar la calidad de los datos antes de la implementación de IA.
Necesidades de Volumen y Variedad de Datos
Los sistemas de IA típicamente requieren volúmenes más grandes de datos que el análisis tradicional para lograr un rendimiento confiable. El volumen exacto depende de la complejidad del problema y el tipo de enfoque de IA, pero los modelos de aprendizaje automático a menudo necesitan miles o millones de puntos de datos para generalizar efectivamente. Conjuntos de datos pequeños pueden llevar al sobreajuste, donde los modelos funcionan bien en datos de entrenamiento pero mal en datos nuevos. Las organizaciones deberían evaluar si tienen suficientes datos históricos o pueden generar datos sintéticos para cumplir con los requisitos de volumen.
La variedad de datos es igualmente importante. Los sistemas de IA se benefician de fuentes de datos diversas que capturan diferentes aspectos del dominio del problema. Esto puede incluir datos estructurados de bases de datos, texto no estructurado de documentos, imágenes, audio o datos de sensores dependiendo de la aplicación. La capacidad de integrar y procesar diferentes tipos de datos es un diferenciador clave para implementaciones de IA exitosas. Las organizaciones deberían inventariar sus fuentes de datos y evaluar si proporcionan suficiente variedad para entrenar modelos robustos.
Requisitos de Etiquetado y Anotación
Los enfoques de aprendizaje automático supervisado requieren datos etiquetados—datos donde la salida o clasificación correcta es conocida. El etiquetado y anotación de datos puede ser consumidor de tiempo y costoso, particularmente para tareas complejas como el reconocimiento de imágenes o el procesamiento de lenguaje natural. Las organizaciones deben evaluar si tienen datos etiquetados existentes, los recursos para etiquetar nuevos datos, o la capacidad de usar enfoques semisupervisados o no supervisados que requieren menos etiquetado.
La calidad de las etiquetas es tan importante como la calidad de los datos mismos. Las etiquetas inconsistentes o incorrectas entrenarán modelos para hacer predicciones incorrectas. Las organizaciones deberían establecer pautas claras de etiquetado, entrenar a los etiquetadores en estas pautas e implementar procesos de control de calidad para asegurar la precisión de las etiquetas. Para aplicaciones de alto riesgo, pueden ser necesarios múltiples etiquetadores independientes para asegurar el consenso y reducir el sesgo.
Frescura y Oportunidad de los Datos
Los sistemas de IA necesitan datos actuales para permanecer relevantes y precisos. Los requisitos de frescura de datos varían según la aplicación—algunos casos de uso pueden funcionar con datos ligeramente obsoletos, mientras que otros requieren actualizaciones en tiempo real o casi en tiempo real. Las organizaciones deberían evaluar su frecuencia de actualización de datos y determinar si cumple con las necesidades de sus aplicaciones de IA. Para aplicaciones sensibles al tiempo como la detección de fraude o mantenimiento predictivo, la frescura de datos es crítica y puede requerir inversión en canalizaciones de datos en tiempo real.
La oportunidad de los datos también se refiere a la capacidad de acceder a los datos cuando se necesitan. Si los datos están disponibles pero son difíciles de acceder debido a restricciones del sistema, permisos o limitaciones técnicas, efectivamente no existen para propósitos de IA. Las organizaciones deberían evaluar la accesibilidad y latencia de los datos para asegurar que los sistemas de IA puedan obtener los datos que necesitan cuando los necesitan.

Riesgos de la Mala Calidad de Datos
Riesgos de Datos Faltantes
Los datos faltantes introducen varios riesgos para los sistemas de IA. Cuando faltan atributos críticos, los modelos pueden aprender patrones incorrectos o hacer predicciones sesgadas. Por ejemplo, si faltan datos demográficos de clientes para ciertos segmentos, un modelo entrenado en esos datos puede funcionar mal para esos segmentos. Los datos faltantes también pueden llevar al sobreajuste si el modelo aprende a depender de patrones que solo existen en los registros completos, reduciendo su capacidad de generalizar.
El impacto comercial de los datos faltantes incluye una mala toma de decisiones, precisión reducida del modelo y sesgo potencial contra grupos subrepresentados. Las organizaciones que no abordan los datos faltantes antes de la implementación de IA pueden descubrir estos problemas solo después de que los modelos se despliegan, requiriendo reentrenamiento costoso y potencialmente dañando relaciones comerciales o reputación.
Riesgos de Datos Incorrectos
Los datos incorrectos—datos que contienen errores, inexactitudes o inconsistencias—plantean riesgos severos para los sistemas de IA. Los modelos entrenados en datos incorrectos aprenderán patrones incorrectos, llevando a predicciones sistemáticamente erróneas. Esto es particularmente peligroso en aplicaciones de alto riesgo como la atención médica, finanzas o sistemas críticos de seguridad donde las predicciones incorrectas pueden tener consecuencias graves.
El impacto de los datos incorrectos se extiende más allá del rendimiento del modelo a la confianza comercial. Si las partes interesadas descubren que los sistemas de IA están tomando decisiones basadas en datos incorrectos, pueden perder confianza en toda la iniciativa de IA. Las organizaciones deberían implementar procesos de validación de datos, mecanismos de detección de errores y auditorías regulares para identificar y corregir datos incorrectos antes de que afecten a los sistemas de IA.
Riesgos de Datos Fragmentados
Los datos fragmentados—datos que existen en silos en diferentes sistemas sin integración—limitan la capacidad de los sistemas de IA para aprender patrones integrales. Cuando los datos están fragmentados, los modelos de IA solo ven imágenes parciales del dominio del problema, llevando a información incompleta y decisiones subóptimas. La fragmentación también hace difícil mantener la consistencia y gobernanza de datos en toda la organización.
Los riesgos comerciales de los datos fragmentados incluyen oportunidades perdidas de información multifuncional, toma de decisiones inconsistente entre departamentos y complejidad aumentada en la gestión de datos. Las organizaciones deberían evaluar su panorama de datos e identificar oportunidades de integración antes de los proyectos de IA para asegurar que los modelos tengan acceso a datos integrales y unificados.
Riesgos de Datos Sin Propietario
Los datos sin propietario—datos sin propiedad o responsabilidad clara—crean problemas de mantenimiento y gobernanza. Cuando nadie es responsable de la calidad, precisión y actualizaciones de los datos, los datos tienden a degradarse con el tiempo. Esta degradación puede impactar significativamente el rendimiento del modelo de IA, particularmente para modelos que requieren entrenamiento continuo con datos frescos.
Los datos sin propietario también crean desafíos de gobernanza. Sin propiedad clara, es difícil establecer políticas de acceso de datos, controles de seguridad y medidas de cumplimiento. Las organizaciones deberían asignar propietarios de datos para conjuntos de datos críticos y establecer responsabilidades claras para el mantenimiento de datos, monitoreo de calidad y gobernanza. Esta estructura de propiedad es esencial para operaciones de IA sostenibles.
Cómo Auditar el Proceso y el Flujo de Datos
Marco de Auditoría de Procesos
Auditar los procesos comerciales antes de la implementación de IA ayuda a identificar variabilidad, cuellos de botella y oportunidades de estandarización. El marco de auditoría de procesos debería mapear los flujos de trabajo actuales, documentar puntos de decisión y evaluar variaciones de proceso en diferentes equipos o ubicaciones. Este mapeo revela dónde los procesos son consistentes y dónde difieren, proporcionando información sobre posibles problemas de calidad de datos.
La auditoría también debería evaluar oportunidades de automatización. Los procesos altamente estandarizados y basados en reglas son buenos candidatos para la mejora con IA, mientras que los procesos altamente variables pueden requerir estandarización antes de que la IA pueda aplicarse efectivamente. Las organizaciones deberían documentar métricas de rendimiento de proceso actuales para establecer líneas base para medir el impacto de IA más tarde.
Auditoría de Flujo de Datos
La auditoría de flujo de datos rastrea cómo los datos se mueven a través de sistemas desde la creación hasta el consumo. Esta auditoría debería identificar fuentes de datos, pasos de transformación, ubicaciones de almacenamiento y patrones de acceso. El objetivo es entender el ciclo de vida completo de los datos e identificar puntos donde la calidad de datos podría degradarse o donde ocurren cuellos de botella.
Los aspectos clave de la auditoría de flujo de datos incluyen mapear el linaje de datos (el camino que toman los datos desde la fuente hasta el destino), identificar reglas de transformación de datos y evaluar la integridad de datos en cada etapa. La auditoría también debería evaluar controles de acceso de datos y medidas de seguridad para asegurar que los sistemas de IA tendrán acceso apropiado a los datos necesarios mientras mantienen el cumplimiento con requisitos de privacidad y seguridad.
El marco de gestión de riesgos de IA del NIST proporciona orientación sobre prácticas de gobernanza y seguridad de datos para sistemas de IA.
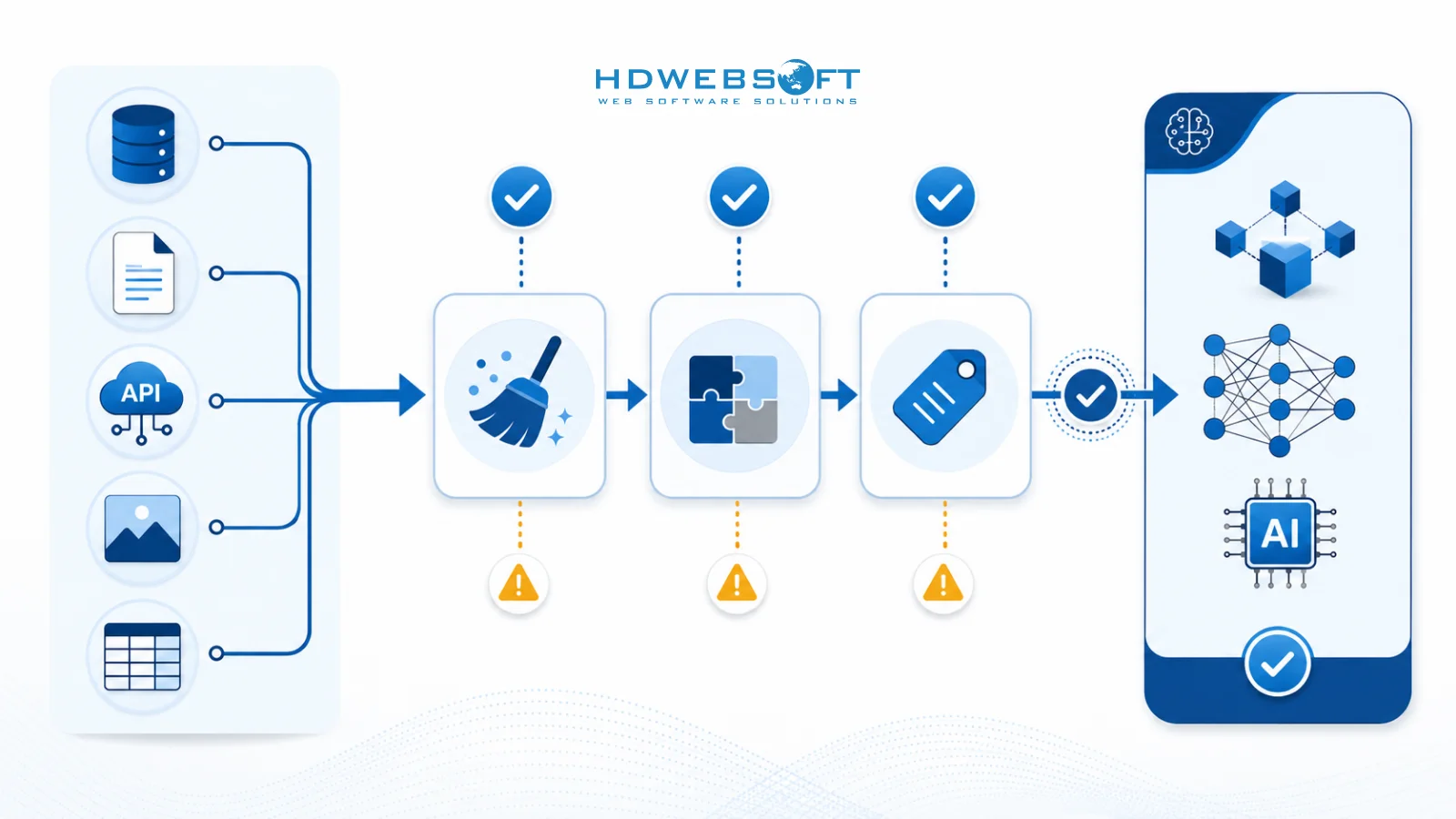
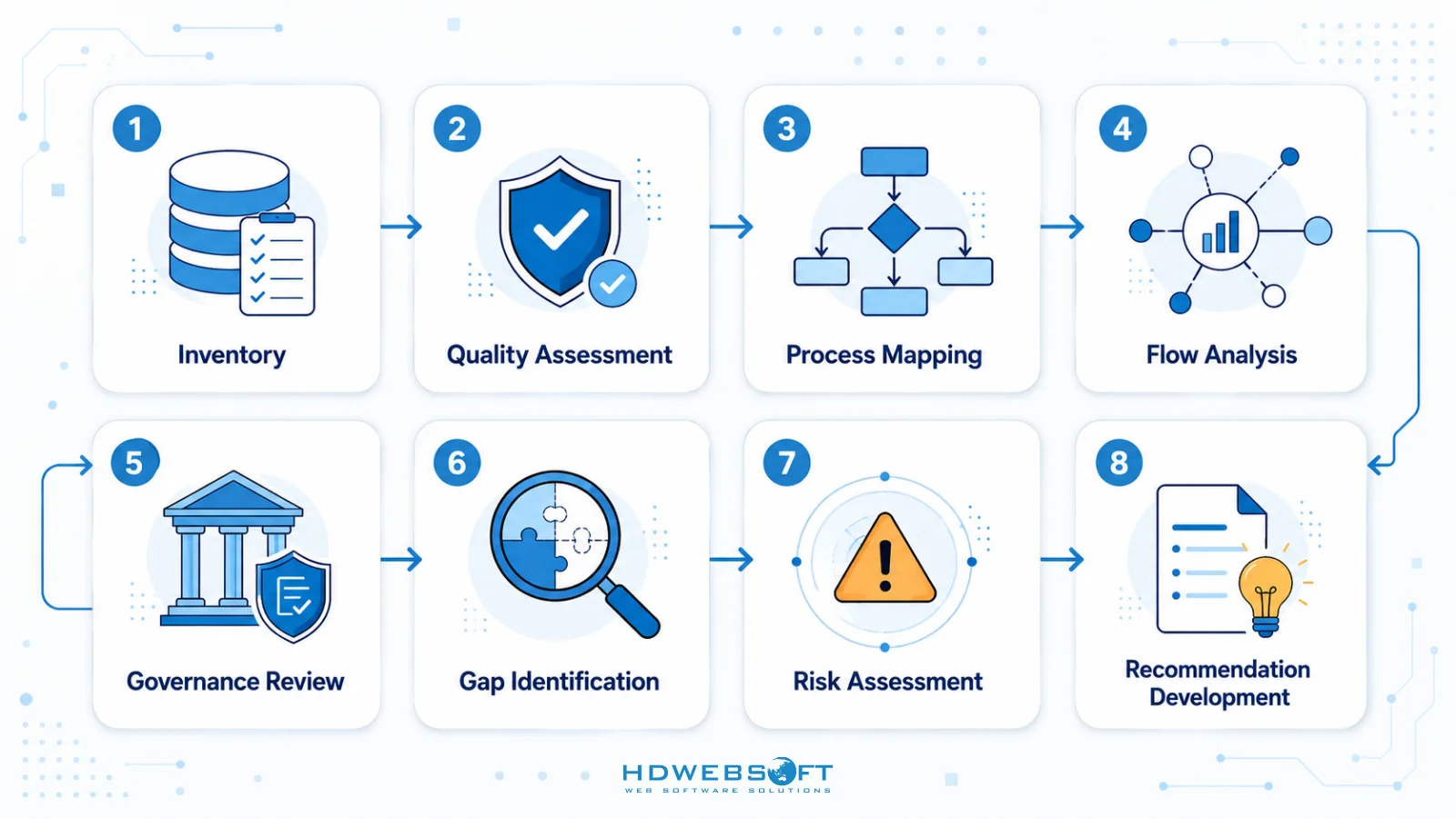
Checklist de Auditoría
Una auditoría integral de preparación de datos debería incluir los siguientes pasos:
- Inventario de Datos: Catalogar todas las fuentes de datos, tipos, volúmenes y ubicaciones
- Evaluación de Calidad: Evaluar precisión, integridad, consistencia y frescura
- Mapeo de Procesos: Documentar procesos comerciales que generan o usan datos
- Análisis de Flujo: Rastrear el movimiento de datos a través de sistemas y transformaciones
- Revisión de Gobernanza: Evaluar propiedad de datos, controles de acceso y cumplimiento
- Identificación de Brechas: Comparar el estado actual contra los requisitos de IA
- Evaluación de Riesgos: Identificar posibles riesgos relacionados con datos para proyectos de IA
- Desarrollo de Recomendaciones: Proponer acciones específicas para abordar brechas y riesgos
Las organizaciones deberían usar este checklist como un enfoque estructurado para la evaluación de preparación de datos, asegurando cobertura integral de todos los aspectos críticos.
Acciones Prioritarias para Preparar Datos y Flujo de Trabajo
Acciones Inmediatas (Semanas 1-2)
Las primeras dos semanas deberían centrarse en actividades fundamentales que proporcionen victorias rápidas y establezcan líneas base. Comience con un inventario integral de datos para entender qué datos existen, dónde se almacenan y quién los posee. Este inventario debería incluir fuentes de datos, volúmenes, formatos y evaluaciones de calidad. Simultáneamente, identifique las fuentes de datos más críticas para sus iniciativas de IA planificadas y priorícelas para atención inmediata.
Establezca líneas base de calidad de datos midiendo los niveles actuales de precisión, integridad y consistencia. Estas líneas base le ayudarán a medir la mejora con el tiempo y establecer expectativas realistas para los cronogramas del proyecto de IA. Comience a documentar procesos comerciales clave que generan o usan datos críticos, enfocándose en áreas con alta variabilidad o problemas de calidad conocidos.
Acciones a Corto Plazo (Meses 1-2)
Los primeros dos meses deberían abordar las brechas más críticas identificadas en la auditoría. Implemente limpieza y estandarización de datos para fuentes de datos prioritarias, enfocándose en precisión, integridad y consistencia. Establezca un marco básico de gobernanza de datos asignando propietarios de datos, definiendo políticas de acceso y documentando estándares de datos.
Comience iniciativas de estandarización de procesos para flujos de trabajo que generan datos críticos. Esto puede implicar crear procedimientos operativos estándar, implementar reglas de validación o entrenar equipos en prácticas consistentes. Configure monitoreo de calidad de datos automatizado donde sea posible para detectar problemas temprano y mantener las mejoras que ha realizado.
Acciones a Mediano Plazo (Meses 3-6)
El enfoque a mediano plazo debería estar en construir capacidades sostenibles y escalar mejoras. Implemente monitoreo de calidad de datos automatizado en todas las fuentes de datos críticas, con alertas para degradación de calidad. Optimice canalizaciones de datos para reducir esfuerzo manual y mejorar confiabilidad. Esto puede implicar invertir en herramientas de integración de datos, implementar gestión de datos maestros o desarrollar procesos de limpieza y validación automatizados.
Implemente automatización de procesos donde se ha logrado estandarización, usando herramientas como automatización de procesos robóticos (RPA) o automatización de flujo de trabajo para reducir error humano y mejorar consistencia. Establezca procesos de mejora continua para revisar regularmente métricas de calidad de datos, rendimiento de proceso y salidas de modelos de IA, haciendo ajustes según sea necesario. Esto crea un ciclo de retroalimentación que asegura que la preparación de datos mejore con el tiempo en lugar de degradarse.
Checklist de Preparación de Datos IA
Use este checklist para evaluar la preparación de datos de su organización antes de la implementación de IA:
Inventario de Datos
- Todas las fuentes de datos críticas identificadas y catalogadas
- Volúmenes y variedades de datos evaluados contra requisitos de IA
- Propietarios de datos asignados para todos los conjuntos de datos críticos
- Patrones de acceso de datos documentados
Calidad de Datos
- Precisión medida y cumple umbrales mínimos (95% o más para campos críticos)
- Integridad evaluada con menos de 5% de valores faltantes para atributos clave
- Consistencia verificada a través de sistemas y períodos de tiempo
- Requisitos de frescura de datos definidos y cumplidos
Estandarización de Procesos
- Procesos comerciales clave documentados
- Variabilidad de proceso evaluada y cuantificada
- Procedimientos operativos estándar creados
- Oportunidades de automatización identificadas
Gobernanza de Datos
- Marco de gobernanza de datos establecido
- Controles de acceso y políticas de seguridad implementados
- Monitoreo de calidad de datos en lugar
- Requisitos de cumplimiento abordados
Preparación Técnica
- Infraestructura de datos evaluada para cargas de trabajo de IA
- Capacidades de integración con sistemas existentes verificadas
- Arquitectura de canalización de datos diseñada
- Consideraciones de escalabilidad abordadas
Errores Comunes de Preparación de Datos
Las organizaciones a menudo subestiman el tiempo y el esfuerzo requeridos para la preparación de datos, asumiendo que es un paso rápido antes del “trabajo real” del desarrollo de IA. En realidad, la preparación de datos típicamente consume 60-80% del tiempo en proyectos de IA. Según la investigación de la industria, omitir una evaluación exhaustiva de datos para ahorrar tiempo generalmente resulta en cronogramas más largos ya que los problemas se descubren a mitad del proyecto.
Otro error común es neglectar la documentación del linaje de datos. Sin documentación clara de dónde provienen los datos, cómo se transforman y qué suposiciones están incorporadas, las organizaciones luchan para solucionar problemas, reproducir resultados o mantener modelos con el tiempo. El linaje de datos es esencial para transparencia, depuración y cumplimiento regulatorio.
Ignorar la variabilidad del proceso también es un error frecuente. Las organizaciones asumen que sus procesos son más consistentes de lo que realmente son, llevando a problemas inesperados de calidad de datos. La estandarización de procesos debería abordarse temprano, ya que a menudo es más difícil de corregir que los problemas técnicos de datos.
Finalmente, muchas organizaciones pasan por alto la importancia de la asignación de propietarios de datos. Sin propiedad clara, la calidad de datos se degrada con el tiempo y nadie es responsable de mantener los estándares necesarios para el éxito de IA. Asignar propietarios de datos y establecer responsabilidades claras es un paso fundamental que no debería omitirse.
Conclusión
La preparación de datos IA no es opcional—es un requisito previo para una implementación exitosa de IA. Las organizaciones que invierten tiempo en evaluar y mejorar su preparación de datos antes de los proyectos de IA reducen significativamente el riesgo de falla y mejoran la probabilidad de lograr valor comercial significativo. La inversión en preparación de datos paga dividendos a través de ciclos de desarrollo más rápidos, modelos más precisos y operaciones de IA sostenibles.
El viaje hacia la preparación de datos requiere atención a aspectos tanto técnicos como organizacionales. Las mejoras técnicas como limpieza, integración e infraestructura de datos son necesarias pero no suficientes. Los cambios organizacionales como estandarización de procesos, marcos de gobernanza y asignación de propietarios de datos son igualmente importantes para el éxito a largo plazo.
Si está planeando iniciativas de IA, comience con una evaluación integral de preparación de datos. HDWEBSOFT puede ayudarle a evaluar su panorama de datos actual, identificar brechas y desarrollar una hoja de ruta para preparar sus datos para el éxito de IA. Nuestros servicios de desarrollo de IA incluyen evaluación de datos, implementación de gobernanza y desarrollo de canalizaciones para asegurar que sus iniciativas de IA tengan la base sólida que necesitan.
Preguntas Frecuentes
¿Cuál es la diferencia entre la calidad de datos general y la preparación de datos IA?
La calidad de datos general se centra en si los datos son precisos y utilizables para análisis y reportes tradicionales. La preparación de datos IA requiere estándares más altos—volúmenes más grandes, tipos más diversos, consistencia más estricta y etiquetado apropiado para aprendizaje automático. Los sistemas de IA también necesitan gobernanza de datos, documentación de linaje y monitoreo continuo de calidad que pueden no ser necesarios para el análisis básico.
¿Cuánto tiempo toma preparar datos para la implementación de IA?
El cronograma varía según el estado actual de sus datos y la complejidad de sus requisitos de IA. Casos de uso simples con buenos datos existentes pueden necesitar 4-6 semanas de preparación. Proyectos complejos con problemas significativos de calidad de datos o desafíos de integración pueden requerir 3-6 meses. Las organizaciones deberían incluir el tiempo de preparación de datos en su planificación de proyecto de IA en lugar de tratarlo como una idea tardía.
¿Cuáles son los errores más comunes de preparación de datos que cometen las organizaciones?
Los errores más comunes incluyen subestimar el tiempo de preparación de datos, omitir la documentación del linaje de datos, ignorar la variabilidad del proceso, neglectar la asignación de propietarios de datos y asumir que la calidad de datos existente es suficiente para IA. Estos errores generalmente llevan a retrasos del proyecto, costos aumentados y, a veces, falla completa del proyecto.
¿Puede la IA funcionar con datos imperfectos, o se requieren datos perfectos?
La IA puede funcionar con datos imperfectos, pero el grado de imperfección importa. Pequeñas cantidades de datos faltantes o ruidosos a menudo pueden manejarse a través de técnicas de limpieza de datos y diseño de modelo robusto. Sin embargo, problemas significativos de calidad de datos impactarán el rendimiento del modelo y pueden hacer que la IA sea impráctica. El objetivo no son datos perfectos sino datos que cumplan umbrales de calidad mínimos para su caso de uso específico.
¿Cómo sé si mi organización está preparada para IA en términos de datos?
Su organización está preparada para IA en términos de datos si tiene volúmenes suficientes de datos relevantes que cumplen umbrales de calidad (precisión, integridad, consistencia), propiedad y gobernanza de datos claras, procesos estandarizados que generan datos consistentes y la infraestructura técnica para soportar cargas de trabajo de IA. Una evaluación formal de preparación de datos puede ayudarle a evaluar estos criterios sistemáticamente e identificar cualquier brecha que necesite abordarse.
