
AIデータレディネスは、組織のデータが人工知能の実装に必要な特定の品質、量、ガバナンス要件を満たしているかどうかを評価します。従来のデータ分析とは異なり、AIシステムは信頼できるモデルをトレーニングし、正確な予測を行うために、データの正確性、完全性、一貫性についてより高い基準を要求します。AIプロジェクトの前にデータレディネスを評価する組織は、プロジェクト失敗のリスクを大幅に減らし、プロジェクト途中での高額な修正を回避します。
重要なポイント
- 標準化されていないプロセスは、AIモデルのパフォーマンスと予測精度に直接影響するデータ品質問題を引き起こします
- データは、AI実装前にバイアスとパフォーマンス問題を回避するために、正確性、完全性、一貫性を含む特定の品質しきい値を満たす必要があります
- 欠落、不正確、断片化、または所有者のいないデータは、バイアスのあるモデルと不適切な意思決定を含む重大なビジネスリスクをもたらします
- AIプロジェクト前の監査プロセスとデータフローは、ボトルネック、ガバナンスのギャップ、統合の課題を特定するのに役立ちます
- 優先行動は、明確なタイムラインを持つデータインベントリ、ガバナンス設定、プロセス標準化に集中する必要があります
AIデータレディネスとは
AIデータレディネスは、人工知能システムの特定の要件に関連する組織のデータインフラと品質の状態を指します。従来の分析はある程度不完全なデータで機能できますが、AIモデル—特に機械学習システム—は、より高いデータ品質、構造、ガバナンス基準を必要とします。データレディネスには、データの保存と処理の技術的側面だけでなく、データがAIアプリケーションにとって信頼できアクセス可能であることを保証するデータ収集、メンテナンス、ガバナンスの周りの組織慣行も含まれます。
一般的なデータ品質とAI固有のデータレディネスの違いは、要件の規模と複雑さにあります。AIシステムは通常、従来の分析よりも大規模なデータ量、より多様なデータタイプ、より厳格な一貫性基準を必要とします。また、モデルトレーニングが信頼できる結果を生成するように、データが適切にラベル付け、文書化、ガバナンスされている必要があります。データレディネス評価をスキップする組織は、プロジェクト途中でこれらの要件を発見することが多く、遅延、コスト増、場合によってはプロジェクトの完全な失敗につながります。
より広範なAIレディネスフレームワークを理解することは、組織がデータ以外の全体的な準備状況を評価するのに役立ちます。
標準化されていないプロセスがAIに与える影響
プロセス標準化とAIパフォーマンスの関係は直接的かつ重要です。ビジネスプロセスが標準化を欠いている場合、それらのプロセスから生成されるデータは一貫性がなくなり、AIシステムが信頼できるパターンを学習することが難しくなります。プロセスの変動性はトレーニングデータにノイズを導入し、パフォーマンスが低下したり一貫性のない予測を行うモデルにつながる可能性があります。例えば、異なるチームが顧客データ入力に異なる手順に従う場合、結果のデータセットは一貫性のない形式、欠落した値、変動する品質を持ち、すべてがAIモデルのパフォーマンスを低下させます。
標準化されていないデータパイプラインは追加の課題を作成します。データが一貫した変換ルールなしに複数のシステムを通過する場合、同じデータポイントが異なる段階で異なる値を持つ可能性があり、AIシステムに混乱を引き起こします。これは、一貫した特徴量エンジニアリングに依存する機械学習モデルにとって特に問題があります。標準化されていないプロセスを持つ組織は、データのクリーニングと正規化に過度な時間を費やすことが多く、モデル開発と最適化に費やすことができる時間を浪費しています。標準化されていないデータパイプラインのコストは、技術的努力を超えてビジネス影響に拡大し、一貫性のないデータに基づく決定は悪い結果につながる可能性があります。
プロセスの変動性は、時間の経過とともにAIシステムを維持する能力にも影響します。トレーニングデータを生成するプロセスが適切な文書化とバージョン管理なしに変更された場合、そのデータでトレーニングされたAIモデルは精度が低下したり、時代遅れになったりする可能性があります。これが、プロセス標準化がデータ品質問題だけでなく、持続可能なAI実装の基本要件である理由です。AIプロジェクトの前にプロセス標準化に取り組む組織は、長期的なAI成功のためにより安定した基盤を作成します。
AIのデータ品質要件
正確性、完全性、一貫性
AIシステムは、すべてのソース間で正確、完全、一貫したデータを必要とします。正確性は、データが体系的なエラーやバイアスなしに実世界の値を正しく表すことを意味します。完全性は、重要な属性がすべての関連レコードに存在することを保証します—欠落した値はモデルトレーニングと予測精度に重大な影響を与える可能性があります。一貫性は、データが異なるシステムと期間にわたって同じ形式、定義、標準に従うことを要求します。一貫性のないデータはAIシステムに混乱を引き起こし、間違ったパターンを学習するモデルにつながる可能性があります。
許容可能なデータ品質のしきい値はユースケースによって異なりますが、一般的なベストプラクティスは、重要なフィールドで少なくとも95%の正確性、重要な属性で5%未満の欠落値、データ定義で100%の一貫性を目指すことを示唆しています。組織は、AIプロジェクトの前にデータ品質ベースラインを確立し、AIライフサイクル全体を通じてこれらの基準を維持するために監視を実装する必要があります。従来の分析では小さく見えるデータ品質問題は、モデルトレーニングの規模と複雑さにより、AIシステムでは大きな問題になる可能性があります。
プロフェッショナルなデータ分析サービスは、AI実装前に組織がデータ品質を評価および改善するのに役立ちます。
データ量と多様性のニーズ
AIシステムは通常、信頼できるパフォーマンスを達成するために従来の分析よりも大規模なデータ量を必要とします。正確な量は問題の複雑さとAIアプローチのタイプによって異なりますが、機械学習モデルは効果的に一般化するために数千または数百万のデータポイントを必要とすることがよくあります。小さなデータセットは過学習につながる可能性があり、モデルはトレーニングデータではうまく機能しますが、新しいデータでは悪く機能します。組織は、十分な履歴データがあるか、合成データを生成して量要件を満たすことができるかを評価する必要があります。
データの多様性も同様に重要です。AIシステムは、問題領域の異なる側面を捉える多様なデータソースから恩恵を受けます。これには、アプリケーションに応じて、データベースからの構造化データ、ドキュメントからの非構造化テキスト、画像、オーディオ、センサーデータが含まれる場合があります。異なるデータタイプを統合して処理する能力は、成功するAI実装の重要な差別化要因です。組織はデータソースをインベントリし、堅牢なモデルをトレーニングするために十分な多様性を提供するかを評価する必要があります。
ラベル付けと注釈の要件
教師あり機械学習アプローチは、正しい出力または分類がわかっているラベル付きデータ—を必要とします。データラベル付けと注釈は、画像認識や自然言語処理などの複雑なタスクにとって時間がかかり、コストがかかる可能性があります。組織は、既存のラベル付きデータがあるか、新しいデータをラベル付けするリソースがあるか、またはラベル付けが少ない半教師ありまたは教師なしアプローチを使用する能力があるかを評価する必要があります。
ラベルの品質はデータ自体の品質と同じくらい重要です。一貫性のないまたは不正確なラベルは、間違った予測を行うモデルをトレーニングします。組織は、明確なラベル付けガイドラインを確立し、これらのガイドラインについてラベラーをトレーニングし、ラベルの正確性を保証するために品質管理プロセスを実装する必要があります。高リスクアプリケーションの場合、コンセンサスを確保しバイアスを減らすために複数の独立したラベラーが必要な場合があります。
データの鮮度と適時性
AIシステムは、関連性を保ち正確であるために現在のデータを必要とします。データの鮮度要件はアプリケーションによって異なります—一部のユースケースは少し古いデータで機能できますが、他のアプリケーションはリアルタイムまたはニアリアルタイムの更新を必要とします。組織は、データ更新頻度を評価し、AIアプリケーションのニーズを満たしているかを判断する必要があります。詐欺検出や予測メンテナンスなどの時間に敏感なアプリケーションの場合、データの鮮度は重要であり、リアルタイムデータパイプラインへの投資が必要な場合があります。
データの適時性は、必要なときにデータにアクセスする能力も指します。データが利用可能だが、システム制限、権限、技術的制限によりアクセスが困難な場合、AIの目的で実質的に存在しません。組織は、AIシステムが必要なときに必要なデータを取得できるように、データアクセシビリティとレイテンシを評価する必要があります。

データ品質が低いリスク
データ欠落のリスク
欠落データはAIシステムにいくつかのリスクをもたらします。重要な属性が欠落している場合、モデルは間違ったパターンを学習したり、バイアスのある予測を行ったりする可能性があります。例えば、特定のセグメントの顧客人口統計データが欠落している場合、そのデータでトレーニングされたモデルはそれらのセグメントでうまく機能しない可能性があります。欠落データは、モデルが完全なレコードにのみ存在するパターンに依存して学習する場合、過学習にもつながる可能性があり、一般化能力を低下させます。
欠落データのビジネス影響には、不適切な意思決定、モデル精度の低下、代表不足グループに対する潜在的なバイアスが含まれます。AI実装前に欠落データに対処しない組織は、モデルが展開された後にのみこれらの問題を発見する可能性があり、高額な再トレーニングが必要となり、ビジネス関係や評判を損なう可能性があります。
不正確なデータのリスク
不正確なデータ—エラー、不正確、または一貫性のないデータを含むデータ—はAIシステムに深刻なリスクをもたらします。不正確なデータでトレーニングされたモデルは間違ったパターンを学習し、体系的に間違った予測につながります。これは、不正確な予測が深刻な結果をもたらす可能性があるヘルスケア、金融、安全重要システムなどの高リスクアプリケーションでは特に危険です。
不正確なデータの影響は、モデルパフォーマンスを超えてビジネス信頼に及びます。ステークホルダーがAIシステムが不正確なデータに基づいて決定を行っていることを発見した場合、AIイニシアチブ全体への信頼を失う可能性があります。組織は、データ検証プロセス、エラー検出メカニズム、定期的な監査を実装して、AIシステムに影響を与える前に不正確なデータを特定して修正する必要があります。
断片化されたデータのリスク
断片化されたデータ—統合なしに異なるシステムに存在するシロのデータ—は、AIシステムが包括的なパターンを学習する能力を制限します。データが断片化されている場合、AIモデルは問題領域の部分的な画像しか見ず、不完全な洞察と最適ではない決定につながります。断片化は、組織全体でデータの一貫性とガバナンスを維持することも困難にします。
断片化されたデータのビジネスリスクには、機能横断的な洞察の機会の損失、部門間での一貫性のない意思決定、データ管理の複雑性の増加が含まれます。組織は、AIプロジェクト前にデータランドスケープを評価し、統合の機会を特定して、モデルが包括的で統一されたデータにアクセスできるようにする必要があります。
所有者のいないデータのリスク
所有者のいないデータ—明確な所有権または説明責任のないデータ—は、メンテナンスとガバナンスの問題を作成します。データ品質、正確性、更新に責任を持つ人がいない場合、データは時間の経過とともに劣化する傾向があります。この劣化は、特に新鮮なデータでの継続的なトレーニングを必要とするモデルの場合、AIモデルのパフォーマンスに重大な影響を与える可能性があります。
所有者のいないデータはガバナンスの課題も作成します。明確な所有権がない場合、データアクセスポリシー、セキュリティコントロール、コンプライアンス措置を確立することが困難です。組織は、重要なデータセットのデータ所有者を割り当て、データメンテナンス、品質監視、ガバナンスの明確な責任を確立する必要があります。この所有権構造は、持続可能なAI運用にとって不可欠です。
プロセスとデータフローの監査方法
プロセス監査フレームワーク
AI実装前のビジネスプロセスの監査は、変動性、ボトルネック、標準化の機会を特定するのに役立ちます。プロセス監査フレームワークは、現在のワークフローをマッピングし、決定ポイントを文書化し、異なるチームまたは場所間でのプロセス変動を評価する必要があります。このマッピングは、プロセスが一貫している場所と異なる場所を明らかにし、潜在的なデータ品質問題への洞察を提供します。
監査は、自動化の機会も評価する必要があります。高度に標準化され、ルールベースのプロセスはAI拡張の良い候補ですが、高度に変動するプロセスは、AIが効果的に適用される前に標準化が必要な場合があります。組織は、後でAIの影響を測定するためのベースラインを確立するために、現在のプロセスパフォーマンスメトリックを文書化する必要があります。
データフロー監査
データフロー監査は、作成から消費までシステムを通じてデータがどのように移動するかを追跡します。この監査は、データソース、変換ステップ、保存場所、アクセスパターンを特定する必要があります。目標は、完全なデータライフサイクルを理解し、データ品質が低下する可能性があるポイントやボトルネックが発生する場所を特定することです。
データフロー監査の重要な側面には、データ系譜(ソースから宛先までのデータパス)のマッピング、データ変換ルールの特定、各段階でのデータ整合性の評価が含まれます。監査は、プライバシーとセキュリティ要件へのコンプライアンスを維持しながら、AIシステムが必要なデータに適切にアクセスできるようにするために、データアクセスコントロールとセキュリティ措置も評価する必要があります。
NIST AIリスク管理フレームワークは、AIシステムのデータガバナンスとセキュリティプラクティスに関するガイダンスを提供しています。
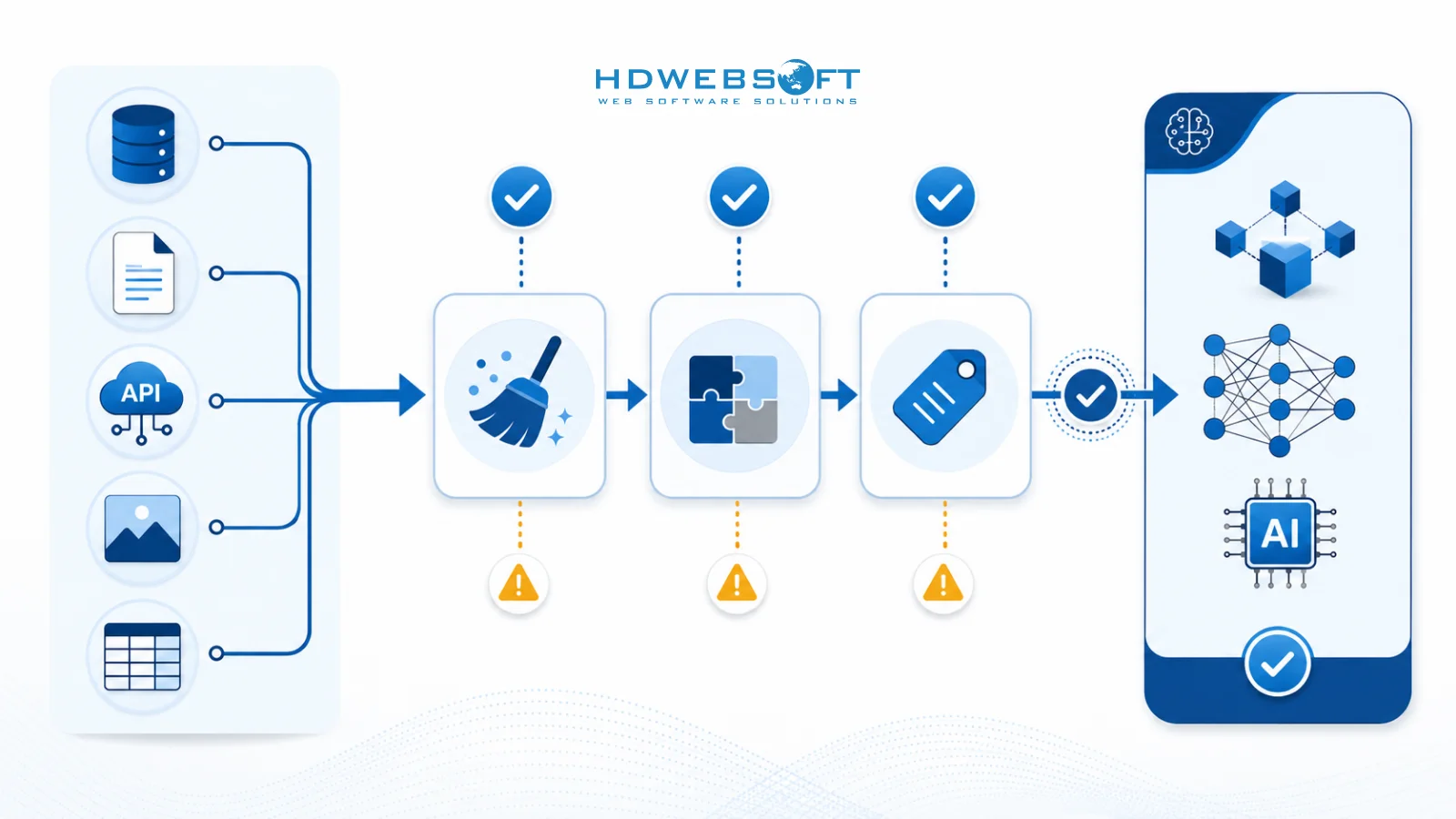
監査チェックリスト
包括的なデータレディネス監査には、次のステップを含める必要があります:
- データインベントリ:すべてのデータソース、タイプ、量、場所をカタログ化
- 品質評価:正確性、完全性、一貫性、鮮度を評価
- プロセスマッピング:データを生成または使用するビジネスプロセスを文書化
- フロー分析:システムと変換を通じたデータ移動を追跡
- ガバナンスレビュー:データ所有権、アクセスコントロール、コンプライアンスを評価
- ギャップ特定:現在の状態をAI要件と比較
- リスク評価:AIプロジェクトの潜在的なデータ関連リスクを特定
- 推奨事項の開発:ギャップとリスクに対処するための具体的なアクションを提案
組織は、このチェックリストをデータレディネス評価の構造化されたアプローチとして使用し、すべての重要な側面を包括的にカバーする必要があります。
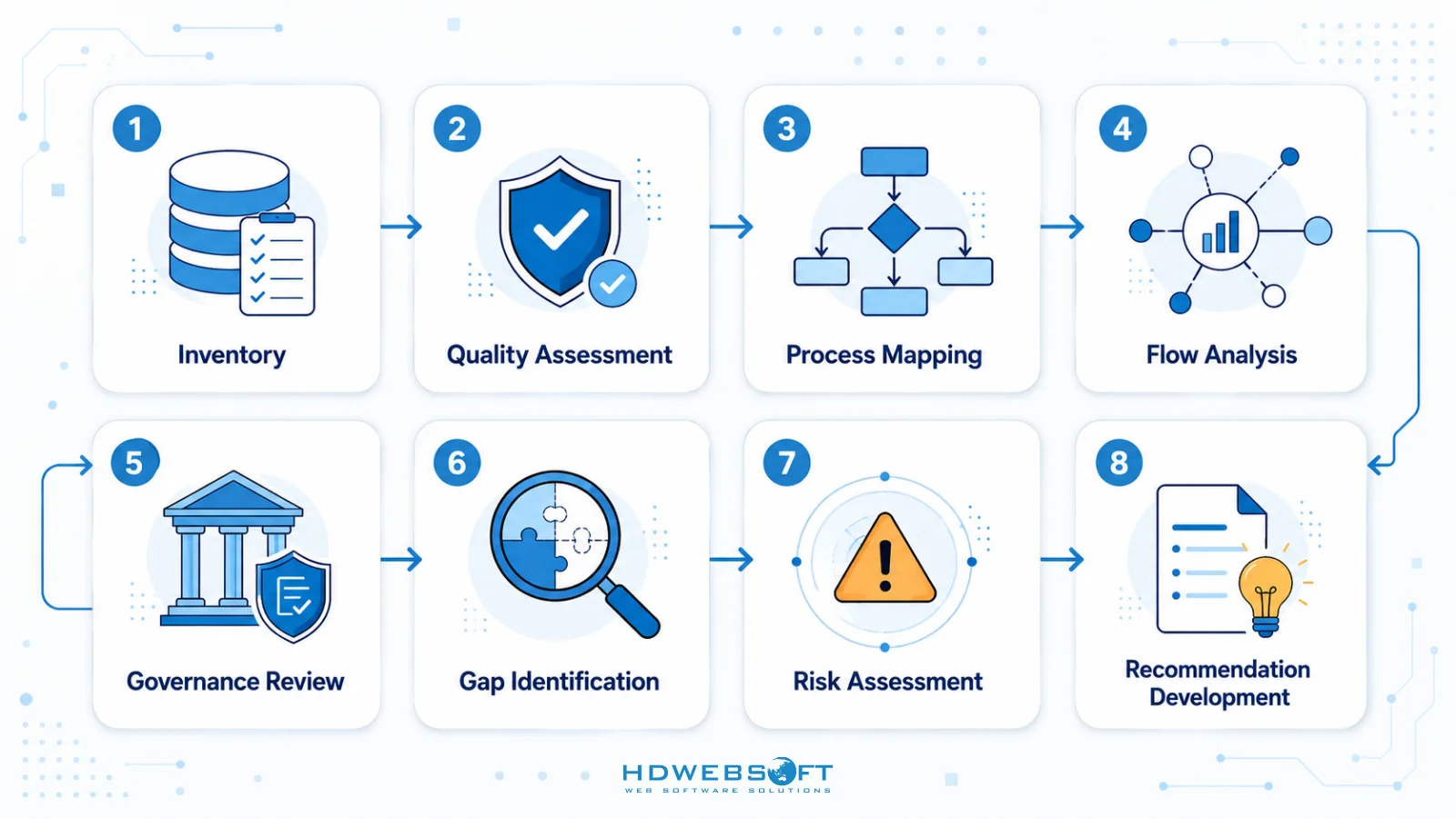
データとワークフローの準備のための優先行動
即時のアクション(週1-2)
最初の2週間は、迅速な勝利を提供しベースラインを確立する基本的な活動に集中する必要があります。データが存在する場所、保存されている場所、誰が所有しているかを理解するための包括的なデータインベントリから始めます。このインベントリには、データソース、量、形式、品質評価が含まれる必要があります。同時に、計画されたAIイニシアチブの最も重要なデータソースを特定し、即時の注意のために優先順位を付けます。
現在の正確性、完全性、一貫性レベルを測定してデータ品質ベースラインを確立します。これらのベースラインは、時間の経過とともに改善を測定し、AIプロジェクトタイムラインの現実的な期待を設定するのに役立ちます。高い変動性または既知の品質問題を持つ領域に焦点を当て、重要なデータを生成または使用する重要なビジネスプロセスの文書化を開始します。
短期のアクション(月1-2)
最初の2ヶ月は、監査で特定された最も重要なギャップに対処する必要があります。正確性、完全性、一貫性に焦点を当て、優先データソースのデータクリーニングと標準化を実装します。データ所有者を割り当て、アクセスポリシーを定義し、データ標準を文書化して、基本的なデータガバナンスフレームワークを確立します。
重要なデータを生成するワークフローのプロセス標準化イニシアチブを開始します。これには、標準作業手順の作成、検証ルールの実装、または一貫した慣行についてチームをトレーニングすることが含まれる場合があります。問題を早期に検出し、行った改善を維持するために、可能な場所で自動化されたデータ品質監視を設定します。
中期のアクション(月3-6)
中期の焦点は、持続可能な能力の構築と改善の拡大にある必要があります。品質低下のアラート付きで、すべての重要なデータソースにわたって自動化されたデータ品質監視を実装します。手作業を減らし信頼性を向上するためにデータパイプラインを最適化します。これには、データ統合ツールへの投資、マスターデータ管理の実装、または自動化されたクリーニングと検証プロセスの開発が含まれる場合があります。
標準化が達成された場所でロボティックプロセス自動化(RPA)やワークフロー自動化などのツールを使用して、プロセス自動化を実装し、人間のエラーを減らし一貫性を向上させます。必要に応じて調整を行いながら、データ品質メトリック、プロセスパフォーマンス、AIモデル出力を定期的にレビューする継続的改善プロセスを確立します。これにより、データレディネスが時間の経過とともに劣化するのではなく、改善されることを保証するフィードバックループが作成されます。
AIデータレディネスチェックリスト
AI実装前に組織のデータレディネスを評価するためにこのチェックリストを使用してください:
データインベントリ
- すべての重要なデータソースが特定されカタログ化されている
- データ量と多様性がAI要件に対して評価されている
- すべての重要なデータセットのデータ所有者が割り当てられている
- データアクセスパターンが文書化されている
データ品質
- 正確性が測定され、最小しきい値(重要なフィールドで95%以上)を満たしている
- 重要な属性で5%未満の欠落値で完全性が評価されている
- システムと期間にわたって一貫性が検証されている
- データの鮮度要件が定義され満たされている
プロセス標準化
- 重要なビジネスプロセスが文書化されている
- プロセス変動性が評価され定量化されている
- 標準作業手順が作成されている
- 自動化の機会が特定されている
データガバナンス
- データガバナンスフレームワークが確立されている
- アクセスコントロールとセキュリティポリシーが実装されている
- データ品質監視が実施されている
- コンプライアンス要件が対処されている
技術的準備
- AIワークロードのデータインフラが評価されている
- 既存のシステムとの統合機能が検証されている
- データパイプラインアーキテクチャが設計されている
- スケーラビリティの考慮事項が対処されている
一般的なデータレディネスの間違い
組織は、データ準備に必要な時間と努力を過小評価し、AI開発の「実際の作業」の前の迅速なステップであると想定することがよくあります。実際には、データ準備は通常、AIプロジェクトの時間の60-80%を消費します。業界調査によると、時間を節約するために徹底的なデータ評価をスキップすると、通常、プロジェクト途中で問題が発見されるため、全体的なタイムラインが長くなります。
もう一つの一般的な間違いは、データ系譜の文書化を無視することです。データがどこから来たか、どのように変換されたか、どのような仮定が組み込まれているかについての明確な文書がない場合、組織は問題のトラブルシューティング、結果の再現、時間の経過とともにモデルの維持に苦労します。データ系譜は、透明性、デバッグ、規制コンプライアンスにとって不可欠です。
プロセス変動性を無視することも頻繁なエラーです。組織は、プロセスが実際よりも一貫していると想定し、予期しないデータ品質問題につながります。プロセス標準化は、技術的なデータ問題よりも修正が難しいため、早期に対処する必要があります。
最後に、多くの組織はデータ所有者の割り当ての重要性を見落としています。明確な所有権がない場合、データ品質は時間の経過とともに劣化し、AI成功に必要な基準を維持する責任を持つ人はいません。データ所有者を割り当て、明確な責任を確立することは、スキップすべきではない基本的なステップです。
結論
AIデータレディネスはオプションではありません—それは成功するAI実装の前提条件です。AIプロジェクト前にデータレディネスの評価と改善に時間を投資する組織は、失敗のリスクを大幅に減らし、有意義なビジネス価値を達成する可能性を高めます。データ準備への投資は、より迅速な開発サイクル、より正確なモデル、持続可能なAI運用を通じて配当を支払います。
データレディネスへの旅には、技術的および組織的側面の両方への注意が必要です。データクリーニング、統合、インフラストラクチャなどの技術的改善は必要ですが十分ではありません。プロセス標準化、ガバナンスフレームワーク、データ所有者の割り当てなどの組織的変更も、長期的な成功にとって同様に重要です。
AIイニシアチブを計画している場合は、包括的なデータレディネス評価から始めてください。HDWEBSOFTは、現在のデータランドスケープを評価し、ギャップを特定し、AI成功のためにデータを準備するロードマップを開発するのに役立ちます。当社のAI開発サービスには、AIイニシアチブが必要とする確実な基盤を確保するためのデータ評価、ガバナンス実装、パイプライン開発が含まれています。
FAQ
一般的なデータ品質とAIデータレディネスの違いは何ですか?
一般的なデータ品質は、データが従来の分析とレポート用に正確で使用可能かどうかに焦点を当てています。AIデータレディネスは、より高い基準—大規模な量、より多様なタイプ、より厳格な一貫性、機械学習のための適切なラベル付け—を必要とします。AIシステムは、基本分析には必要ない可能性があるデータガバナンス、データ系譜文書化、継続的な品質監視も必要とします。
AI実装のためにデータを準備するにはどのくらい時間がかかりますか?
タイムラインは、現在のデータの状態とAI要件の複雑さによって異なります。良い既存データを持つ単純なユースケースは、4-6週間の準備が必要な場合があります。重大なデータ品質問題または統合の課題を持つ複雑なプロジェクトは、3-6ヶ月を必要とする場合があります。組織は、データ準備時間をAIプロジェクト計画に含める必要があり、事後考慮として扱うべきではありません。
組織が犯す一般的なデータレディネスの間違いは何ですか?
一般的な間違いには、データ準備時間の過小評価、データ系譜文書化のスキップ、プロセス変動性の無視、データ所有者割り当ての無視、既存のデータ品質がAIにとって十分であると想定することが含まれます。これらの間違いは通常、プロジェクト遅延、コスト増、場合によってはプロジェクトの完全な失敗につながります。
AIは不完全なデータで機能できますか、それとも完全なデータが必要ですか?
AIは不完全なデータで機能できますが、不完全さの程度が重要です。少量の欠落またはノイズの多いデータは、データクリーニング技術と堅牢なモデル設計を通じて処理できることがよくあります。ただし、重大なデータ品質問題はモデルパフォーマンスに影響し、AIを実用的でなくする可能性があります。目標は完全なデータではなく、特定のユースケースの最小品質しきい値を満たすデータです。
データに関して組織がAIの準備ができているかどうかをどう知ることができますか?
組織は、品質しきい値(正確性、完全性、一貫性)を満たす関連データの十分な量、明確なデータ所有権とガバナンス、一貫したデータを生成する標準化されたプロセス、AIワークロードをサポートする技術インフラストラクチャを持っている場合、データに関してAIの準備ができています。正式なデータレディネス評価は、これらの基準を体系的に評価し、対処が必要なギャップを特定するのに役立ちます。
