
La préparation des données IA évalue si les données de votre organisation répondent aux exigences spécifiques de qualité, de quantité et de gouvernance nécessaires pour une mise en œuvre réussie de l’intelligence artificielle. Contrairement à l’analyse de données traditionnelle, les systèmes IA exigent des normes plus élevées en matière de précision, d’exhaustivité et de cohérence des données pour former des modèles fiables et faire des prédictions précises. Les organisations qui évaluent la préparation des données avant les projets IA réduisent considérablement le risque d’échec du projet et évitent des corrections coûteuses en cours de projet.
Points Clés
- Les processus non standardisés créent des problèmes de qualité des données qui impactent directement les performances des modèles IA et la précision des prédictions
- Les données doivent répondre à des seuils de qualité spécifiques incluant la précision, l’exhaustivité et la cohérence avant la mise en œuvre de l’IA pour éviter les biais et les problèmes de performance
- Les données manquantes, incorrectes, fragmentées ou sans propriétaire introduisent des risques commerciaux importants incluant des modèles biaisés et une mauvaise prise de décision
- Le processus d’audit et le flux de données avant les projets IA aident à identifier les goulots d’étranglement, les lacunes de gouvernance et les défis d’intégration
- Les actions prioritaires devraient se concentrer sur l’inventaire des données, la mise en place de la gouvernance et la standardisation des processus avec des délais clairs
Qu’est-ce que la Préparation des Données IA ?
La préparation des données IA fait référence à l’état de l’infrastructure de données et de la qualité de votre organisation par rapport aux exigences spécifiques des systèmes d’intelligence artificielle. Alors que l’analyse traditionnelle peut fonctionner avec des données imparfaites dans une certaine mesure, les modèles IA—en particulier les systèmes d’apprentissage automatique—nécessitent des normes plus élevées de qualité, de structure et de gouvernance des données. La préparation des données englobe non seulement les aspects techniques du stockage et du traitement des données, mais aussi les pratiques organisationnelles autour de la collecte, de la maintenance et de la gouvernance des données qui garantissent que les données restent fiables et accessibles pour les applications IA.
La différence entre la qualité des données générale et la préparation des données spécifique à l’IA réside dans l’échelle et la complexité des exigences. Les systèmes IA ont généralement besoin de volumes de données plus importants, de types de données plus diversifiés et de normes de cohérence plus strictes que l’analyse traditionnelle. Ils nécessitent également que les données soient correctement étiquetées, documentées et gouvernées pour garantir que la formation des modèles produit des résultats fiables. Les organisations qui ignorent l’évaluation de la préparation des données découvrent souvent ces exigences en cours de projet, ce qui entraîne des retards, des coûts accrus et parfois un échec complet du projet.
Comprendre le cadre de préparation IA plus large peut aider les organisations à évaluer leur préparation globale au-delà des seules données.
Comment les Processus Non Standardisés Impactent l’IA
Le lien entre la standardisation des processus et les performances de l’IA est direct et significatif. Lorsque les processus commerciaux manquent de standardisation, les données générées par ces processus deviennent incohérentes, ce qui rend difficile pour les systèmes IA d’apprendre des modèles fiables. La variabilité des processus introduit du bruit dans les données de formation, ce qui peut conduire à des modèles qui fonctionnent mal ou font des prédictions incohérentes. Par exemple, si différentes équipes suivent des procédures différentes pour la saisie des données clients, l’ensemble de données résultant aura des formats incohérents, des valeurs manquantes et une qualité variable—tous ces éléments dégradent les performances des modèles IA.
Les pipelines de données non standardisés créent des défis supplémentaires. Lorsque les données traversent plusieurs systèmes sans règles de transformation cohérentes, le même point de données peut avoir des valeurs différentes à différentes étapes, créant de la confusion pour les systèmes IA. C’est particulièrement problématique pour les modèles d’apprentissage automatique qui s’appuient sur une ingénierie de caractéristiques cohérente. Les organisations avec des processus non standardisés passent souvent un temps excessif à nettoyer et normaliser les données—du temps qui pourrait être mieux consacré au développement et à l’optimisation des modèles. Le coût des pipelines de données non standardisés s’étend au-delà de l’effort technique pour inclure l’impact commercial, car les décisions basées sur des données incohérentes peuvent conduire à de mauvais résultats.
La variabilité des processus affecte également la capacité de maintenir les systèmes IA au fil du temps. Si les processus qui génèrent les données de formation changent sans documentation appropriée et contrôle de version, les modèles IA formés sur ces données peuvent devenir moins précis voire obsolètes. C’est pourquoi la standardisation des processus n’est pas seulement un problème de qualité des données mais une exigence fondamentale pour une mise en œuvre de l’IA durable. Les organisations qui abordent la standardisation des processus avant les projets IA créent une base plus stable pour le succès à long terme de l’IA.
Exigences de Qualité des Données pour l’IA
Précision, Exhaustivité et Cohérence
Les systèmes IA nécessitent des données précises, complètes et cohérentes sur toutes les sources. La précision signifie que les données représentent correctement les valeurs du monde réel sans erreurs systématiques ou biais. L’exhaustivité garantit que les attributs critiques sont présents pour tous les enregistrements pertinents—les valeurs manquantes peuvent avoir un impact significatif sur la formation des modèles et la précision des prédictions. La cohérence exige que les données suivent les mêmes formats, définitions et normes sur différents systèmes et périodes. Des données incohérentes créent de la confusion pour les systèmes IA et peuvent conduire à des modèles qui apprennent des modèles incorrects.
Le seuil de qualité des données acceptable varie selon le cas d’utilisation, mais les meilleures pratiques générales suggèrent de viser au moins 95% de précision dans les champs critiques, moins de 5% de valeurs manquantes pour les attributs clés et 100% de cohérence dans les définitions de données. Les organisations devraient établir des lignes de base de qualité des données avant les projets IA et mettre en œuvre une surveillance pour maintenir ces normes tout au long du cycle de vie de l’IA. Les problèmes de qualité des données qui semblent mineurs dans l’analyse traditionnelle peuvent devenir des problèmes majeurs dans les systèmes IA en raison de l’échelle et de la complexité de la formation des modèles.
Des services professionnels d’analyse de données peuvent aider les organisations à évaluer et améliorer la qualité des données avant la mise en œuvre de l’IA.
Besoins en Volume et Variété de Données
Les systèmes IA nécessitent généralement des volumes de données plus importants que l’analyse traditionnelle pour atteindre des performances fiables. Le volume exact dépend de la complexité du problème et du type d’approche IA, mais les modèles d’apprentissage automatique ont souvent besoin de milliers ou millions de points de données pour généraliser efficacement. De petits ensembles de données peuvent conduire au surapprentissage, où les modèles fonctionnent bien sur les données de formation mais mal sur de nouvelles données. Les organisations devraient évaluer si elles ont suffisamment de données historiques ou peuvent générer des données synthétiques pour répondre aux exigences de volume.
La variété des données est tout aussi importante. Les systèmes IA bénéficient de sources de données diversifiées qui capturent différents aspects du domaine du problème. Cela peut inclure des données structurées de bases de données, du texte non structuré de documents, des images, de l’audio ou des données de capteurs selon l’application. La capacité d’intégrer et de traiter différents types de données est un différenciateur clé pour les implémentations IA réussies. Les organisations devraient inventorier leurs sources de données et évaluer si elles fournissent une variété suffisante pour former des modèles robustes.
Exigences d’Étiquetage et d’Annotation
Les approches d’apprentissage automatique supervisé nécessitent des données étiquetées—données où la sortie ou la classification correcte est connue. L’étiquetage et l’annotation des données peuvent être chronophages et coûteux, en particulier pour des tâches complexes comme la reconnaissance d’images ou le traitement du langage naturel. Les organisations doivent évaluer si elles ont des données étiquetées existantes, les ressources pour étiqueter de nouvelles données, ou la capacité d’utiliser des approches semi-supervisées ou non supervisées nécessitant moins d’étiquetage.
La qualité des étiquettes est aussi importante que la qualité des données elles-mêmes. Des étiquettes incohérentes ou incorrectes formeront des modèles à faire de mauvaises prédictions. Les organisations devraient établir des directives d’étiquetage claires, former les étiqueteurs sur ces directives et mettre en œuvre des processus de contrôle de qualité pour garantir la précision des étiquettes. Pour les applications à enjeux élevés, plusieurs étiqueteurs indépendants peuvent être nécessaires pour garantir le consensus et réduire les biais.
Fraîcheur et Actualité des Données
Les systèmes IA ont besoin de données actuelles pour rester pertinentes et précises. Les exigences de fraîcheur des données varient selon l’application—certains cas d’utilisation peuvent fonctionner avec des données légèrement obsolètes, tandis que d’autres nécessitent des mises à jour en temps réel ou quasi temps réel. Les organisations devraient évaluer leur fréquence de mise à jour des données et déterminer si elle répond aux besoins de leurs applications IA. Pour les applications sensibles au temps comme la détection de fraude ou la maintenance prédictive, la fraîcheur des données est critique et peut nécessiter un investissement dans des pipelines de données en temps réel.
L’actualité des données fait également référence à la capacité d’accéder aux données lorsque nécessaire. Si les données sont disponibles mais difficiles d’accès en raison de contraintes système, d’autorisations ou de limitations techniques, elles n’existent pas effectivement pour les besoins de l’IA. Les organisations devraient évaluer l’accessibilité et la latence des données pour garantir que les systèmes IA peuvent obtenir les données dont ils ont besoin quand ils en ont besoin.

Risques d’une Mauvaise Qualité des Données
Risques de Données Manquantes
Les données manquantes introduisent plusieurs risques pour les systèmes IA. Lorsque des attributs critiques sont manquants, les modèles peuvent apprendre des modèles incorrects ou faire des prédictions biaisées. Par exemple, si les données démographiques des clients sont manquantes pour certains segments, un modèle formé sur ces données peut fonctionner mal pour ces segments. Les données manquantes peuvent également conduire au surapprentissage si le modèle apprend à s’appuyer sur des modèles qui n’existent que dans les enregistrements complets, réduisant sa capacité à généraliser.
L’impact commercial des données manquantes inclut une mauvaise prise de décision, une précision réduite des modèles et un biais potentiel contre les groupes sous-représentés. Les organisations qui n’abordent pas les données manquantes avant la mise en œuvre de l’IA peuvent découvrir ces problèmes seulement après le déploiement des modèles, nécessitant un reformation coûteux et potentiellement endommageant les relations commerciales ou la réputation.
Risques de Données Incorrectes
Les données incorrectes—données contenant des erreurs, des inexactitudes ou des incohérences—posent des risques graves pour les systèmes IA. Les modèles formés sur des données incorrectes apprendront des modèles incorrects, conduisant à des prédictions systématiquement erronées. C’est particulièrement dangereux dans les applications à enjeux élevés comme les soins de santé, la finance ou les systèmes critiques de sécurité où des prédictions incorrectes peuvent avoir des conséquences graves.
L’impact des données incorrectes s’étend au-delà des performances du modèle à la confiance commerciale. Si les parties prenantes découvrent que les systèmes IA prennent des décisions basées sur des données incorrectes, elles peuvent perdre confiance dans toute l’initiative IA. Les organisations devraient mettre en œuvre des processus de validation des données, des mécanismes de détection d’erreurs et des audits réguliers pour identifier et corriger les données incorrectes avant qu’elles n’affectent les systèmes IA.
Risques de Données Fragmentées
Les données fragmentées—données existant dans des silos sur différents systèmes sans intégration—limitent la capacité des systèmes IA à apprendre des modèles complets. Lorsque les données sont fragmentées, les modèles IA ne voient que des images partielles du domaine du problème, conduisant à des informations incomplètes et des décisions sous-optimales. La fragmentation rend également difficile le maintien de la cohérence et de la gouvernance des données dans toute l’organisation.
Les risques commerciaux des données fragmentées incluent des opportunités manquées d’informations interfonctionnelles, une prise de décision incohérente entre les départements et une complexité accrue dans la gestion des données. Les organisations devraient évaluer leur paysage de données et identifier les opportunités d’intégration avant les projets IA pour garantir que les modèles ont accès à des données complètes et unifiées.
Risques de Données Sans Propriétaire
Les données sans propriétaire—données sans propriété ou responsabilité claire—créent des problèmes de maintenance et de gouvernance. Lorsque personne n’est responsable de la qualité, de la précision et des mises à jour des données, les données ont tendance à se dégrader au fil du temps. Cette dégradation peut avoir un impact significatif sur les performances des modèles IA, en particulier pour les modèles nécessitant une formation continue avec des données fraîches.
Les données sans propriétaire créent également des défis de gouvernance. Sans propriété claire, il est difficile d’établir des politiques d’accès aux données, des contrôles de sécurité et des mesures de conformité. Les organisations devraient assigner des propriétaires de données pour les ensembles de données critiques et établir des responsabilités claires pour la maintenance des données, la surveillance de la qualité et la gouvernance. Cette structure de propriété est essentielle pour des opérations IA durables.
Comment Auditer le Processus et le Flux de Données
Cadre d’Audit de Processus
L’audit des processus commerciaux avant la mise en œuvre de l’IA aide à identifier la variabilité, les goulots d’étranglement et les opportunités de standardisation. Le cadre d’audit de processus devrait mapper les flux de travail actuels, documenter les points de décision et évaluer les variations de processus entre différentes équipes ou sites. Ce mappage révèle où les processus sont cohérents et où ils diffèrent, fournissant un aperçu des problèmes potentiels de qualité des données.
L’audit devrait également évaluer les opportunités d’automatisation. Les processus hautement standardisés et basés sur des règles sont de bons candidats pour l’augmentation par l’IA, tandis que les processus hautement variables peuvent nécessiter une standardisation avant que l’IA puisse être appliquée efficacement. Les organisations devraient documenter les métriques de performance des processus actuels pour établir des lignes de base pour mesurer l’impact de l’IA plus tard.
Audit du Flux de Données
L’audit du flux de données trace comment les données se déplacent à travers les systèmes de la création à la consommation. Cet audit devrait identifier les sources de données, les étapes de transformation, les emplacements de stockage et les modèles d’accès. L’objectif est de comprendre le cycle de vie complet des données et d’identifier les points où la qualité des données pourrait se dégrader ou où des goulots d’étranglement se produisent.
Les aspects clés de l’audit du flux de données incluent le mappage de la lignée des données (le chemin que les données prennent de la source à la destination), l’identification des règles de transformation des données et l’évaluation de l’intégrité des données à chaque étape. L’audit devrait également évaluer les contrôles d’accès aux données et les mesures de sécurité pour garantir que les systèmes IA auront un accès approprié aux données nécessaires tout en maintenant la conformité avec les exigences de confidentialité et de sécurité.
Le cadre de gestion des risques IA du NIST fournit des conseils sur les pratiques de gouvernance et de sécurité des données pour les systèmes IA.
Checklist d’Audit
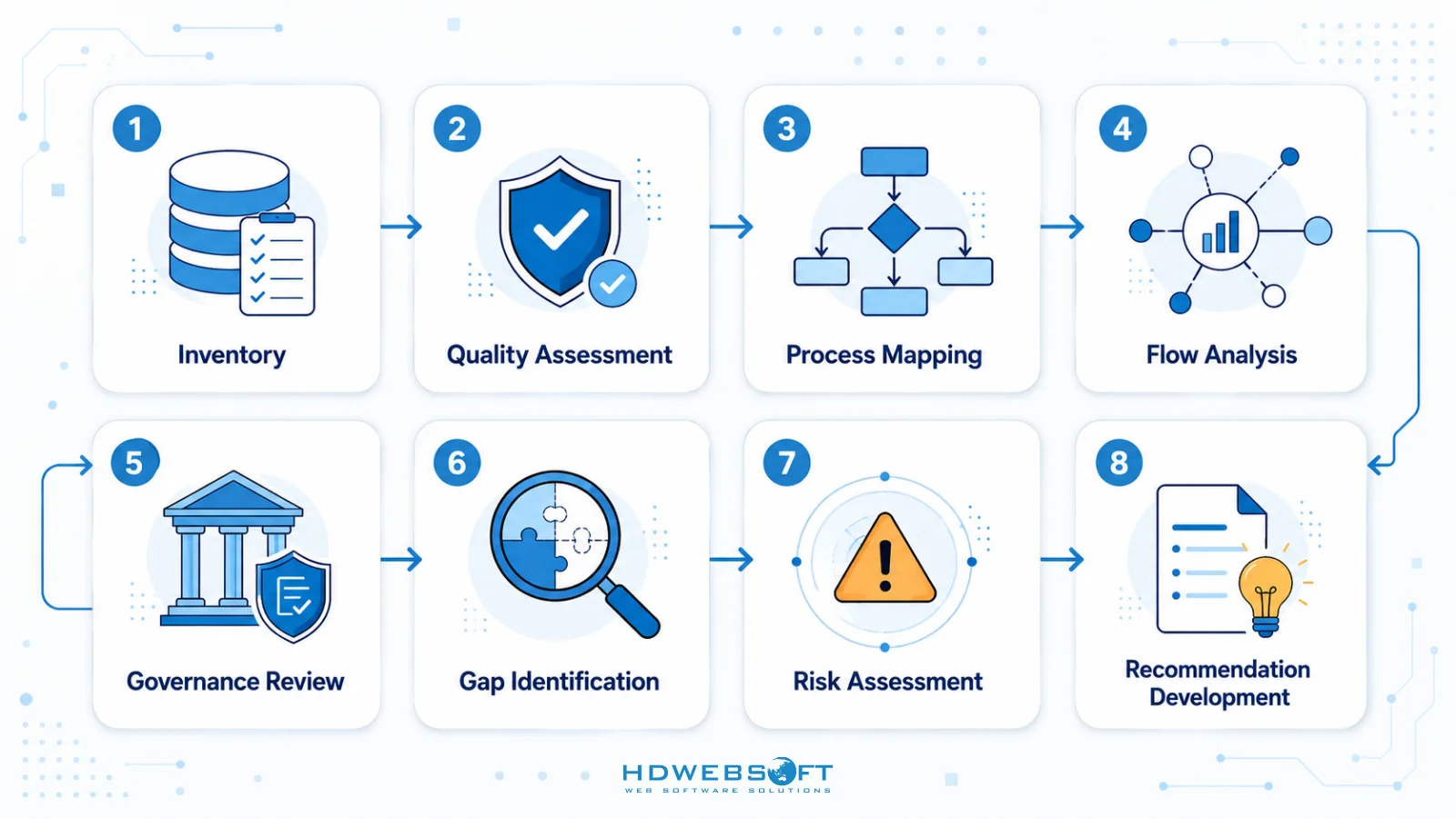
Un audit complet de préparation des données devrait inclure les étapes suivantes :
- Inventaire des Données : Cataloguer toutes les sources de données, types, volumes et emplacements
- Évaluation de la Qualité : Évaluer la précision, l’exhaustivité, la cohérence et la fraîcheur
- Mappage des Processus : Documenter les processus commerciaux qui génèrent ou utilisent des données
- Analyse du Flux : Tracer le mouvement des données à travers les systèmes et les transformations
- Examen de la Gouvernance : Évaluer la propriété des données, les contrôles d’accès et la conformité
- Identification des Lacunes : Comparer l’état actuel avec les exigences de l’IA
- Évaluation des Risques : Identifier les risques potentiels liés aux données pour les projets IA
- Développement de Recommandations : Proposer des actions spécifiques pour répondre aux lacunes et risques
Les organisations devraient utiliser cette checklist comme une approche structurée de l’évaluation de la préparation des données, garantissant une couverture complète de tous les aspects critiques.
Actions Prioritaires pour Préparer les Données et le Flux de Travail
Actions Immédiates (Semaines 1-2)
Les deux premières semaines devraient se concentrer sur les activités fondamentales qui fournissent des victoires rapides et établissent des lignes de base. Commencez par un inventaire complet des données pour comprendre quelles données existent, où elles sont stockées et qui les possède. Cet inventaire devrait inclure les sources de données, les volumes, les formats et les évaluations de qualité. Simultanément, identifiez les sources de données les plus critiques pour vos initiatives IA planifiées et priorisez-les pour une attention immédiate.
Établissez des lignes de base de qualité des données en mesurant les niveaux actuels de précision, d’exhaustivité et de cohérence. Ces lignes de base vous aideront à mesurer l’amélioration au fil du temps et à établir des attentes réalistes pour les délais des projets IA. Commencez à documenter les processus commerciaux clés qui génèrent ou utilisent des données critiques, en vous concentrant sur les zones à forte variabilité ou aux problèmes de qualité connus.
Actions à Court Terme (Mois 1-2)
Les deux premiers mois devraient répondre aux lacunes les plus critiques identifiées lors de l’audit. Mettez en œuvre le nettoyage et la standardisation des données pour les sources de données prioritaires, en vous concentrant sur la précision, l’exhaustivité et la cohérence. Établissez un cadre de gouvernance des données de base en assignant des propriétaires de données, en définissant des politiques d’accès et en documentant les normes de données.
Commencez les initiatives de standardisation des processus pour les flux de travail qui génèrent des données critiques. Cela peut impliquer la création de procédures opérationnelles standard, la mise en œuvre de règles de validation ou la formation des équipes sur des pratiques cohérentes. Mettez en place une surveillance automatisée de la qualité des données lorsque possible pour détecter les problèmes tôt et maintenir les améliorations que vous avez apportées.
Actions à Moyen Terme (Mois 3-6)
Le focus à moyen terme devrait être sur la construction de capacités durables et l’expansion des améliorations. Mettez en œuvre une surveillance automatisée de la qualité des données sur toutes les sources de données critiques, avec des alertes pour la dégradation de la qualité. Optimisez les pipelines de données pour réduire l’effort manuel et améliorer la fiabilité. Cela peut impliquer un investissement dans des outils d’intégration de données, la mise en œuvre de la gestion des données de référence ou le développement de processus de nettoyage et de validation automatisés.
Mettez en œuvre l’automatisation des processus là où la standardisation a été réalisée, en utilisant des outils comme l’automatisation des processus robotiques (RPA) ou l’automatisation des flux de travail pour réduire l’erreur humaine et améliorer la cohérence. Établissez des processus d’amélioration continue pour examiner régulièrement les métriques de qualité des données, les performances des processus et les sorties des modèles IA, en apportant des ajustements selon les besoins. Cela crée une boucle de rétroaction qui garantit que la préparation des données s’améliore au fil du temps plutôt que de se dégrader.
Checklist de Préparation des Données IA
Utilisez cette checklist pour évaluer la préparation des données de votre organisation avant la mise en œuvre de l’IA :
Inventaire des Données
- Toutes les sources de données critiques identifiées et cataloguées
- Volumes et variétés de données évalués par rapport aux exigences de l’IA
- Propriétaires de données assignés pour tous les ensembles de données critiques
- Modèles d’accès aux données documentés
Qualité des Données
- Précision mesurée et répond aux seuils minimums (95% ou plus pour les champs critiques)
- Exhaustivité évaluée avec moins de 5% de valeurs manquantes pour les attributs clés
- Cohérence vérifiée sur les systèmes et les périodes
- Exigences de fraîcheur des données définies et satisfaites
Standardisation des Processus
- Processus commerciaux clés documentés
- Variabilité des processus évaluée et quantifiée
- Procédures opérationnelles standard créées
- Opportunités d’automatisation identifiées
Gouvernance des Données
- Cadre de gouvernance des données établi
- Contrôles d’accès et politiques de sécurité mis en œuvre
- Surveillance de la qualité des données en place
- Exigences de conformité adressées
Préparation Technique
- Infrastructure des données évaluée pour les charges de travail IA
- Capacités d’intégration avec les systèmes existants vérifiées
- Architecture du pipeline de données conçue
- Considérations d’évolutivité adressées
Erreurs Courantes de Préparation des Données
Les organisations sous-estiment souvent le temps et l’effort nécessaires pour la préparation des données, supposant que c’est une étape rapide avant le “vrai travail” du développement de l’IA. En réalité, la préparation des données consomme généralement 60-80% du temps dans les projets IA. Selon la recherche industrielle, ignorer une évaluation approfondie des données pour gagner du temps entraîne généralement des délais globaux plus longs car les problèmes sont découverts en cours de projet.
Une autre erreur courante est de négliger la documentation de la lignée des données. Sans documentation claire de l’origine des données, de leur transformation et des hypothèses intégrées, les organisations ont du mal à dépanner les problèmes, reproduire les résultats ou maintenir les modèles au fil du temps. La lignée des données est essentielle pour la transparence, le débogage et la conformité réglementaire.
Ignorer la variabilité des processus est également une erreur fréquente. Les organisations supposent que leurs processus sont plus cohérents qu’ils ne le sont en réalité, conduisant à des problèmes inattendus de qualité des données. La standardisation des processus devrait être abordée tôt, car elle est souvent plus difficile à corriger que les problèmes techniques de données.
Enfin, de nombreuses organisations négligent l’importance de l’assignation de propriétaires de données. Sans propriété claire, la qualité des données se dégrade au fil du temps et personne n’est responsable de maintenir les normes nécessaires au succès de l’IA. Assigner des propriétaires de données et établir des responsabilités claires est une étape fondamentale qui ne devrait pas être ignorée.
Conclusion
La préparation des données IA n’est pas optionnelle—c’est une condition préalable à une mise en œuvre réussie de l’IA. Les organisations qui investissent du temps dans l’évaluation et l’amélioration de leur préparation des données avant les projets IA réduisent considérablement le risque d’échec et améliorent la probabilité de réaliser une valeur commerciale significative. L’investissement dans la préparation des données rapporte des dividendes grâce à des cycles de développement plus rapides, des modèles plus précis et des opérations IA durables.
Le parcours vers la préparation des données nécessite une attention aux aspects techniques et organisationnels. Les améliorations techniques comme le nettoyage, l’intégration et l’infrastructure des données sont nécessaires mais pas suffisantes. Les changements organisationnels comme la standardisation des processus, les cadres de gouvernance et l’assignation de propriétaires de données sont tout aussi importants pour le succès à long terme.
Si vous planifiez des initiatives IA, commencez par une évaluation complète de la préparation des données. HDWEBSOFT peut vous aider à évaluer votre paysage de données actuel, identifier les lacunes et développer une feuille de route pour préparer vos données au succès de l’IA. Nos services de développement IA incluent l’évaluation des données, la mise en œuvre de la gouvernance et le développement de pipelines pour garantir que vos initiatives IA ont la base solide dont elles ont besoin.
FAQ
Quelle est la différence entre la qualité des données générale et la préparation des données IA ?
La qualité des données générale se concentre sur la précision et l’utilisabilité des données pour l’analyse et le reporting traditionnels. La préparation des données IA exige des normes plus élevées—des volumes plus importants, des types plus diversifiés, une cohérence plus stricte et un étiquetage approprié pour l’apprentissage automatique. Les systèmes IA ont également besoin de gouvernance des données, de documentation de la lignée et d’une surveillance continue de la qualité qui peuvent ne pas être nécessaires pour l’analyse de base.
Combien de temps faut-il pour préparer les données pour la mise en œuvre de l’IA ?
Le calendrier varie en fonction de l’état actuel de vos données et de la complexité de vos exigences IA. Les cas d’utilisation simples avec de bonnes données existantes peuvent nécessiter 4-6 semaines de préparation. Les projets complexes avec des problèmes de qualité de données significatifs ou des défis d’intégration peuvent nécessiter 3-6 mois. Les organisations devraient inclure le temps de préparation des données dans leur planification de projet IA plutôt que de le considérer comme une réflexion après coup.
Quelles sont les erreurs les plus courantes de préparation des données que les organisations commettent ?
Les erreurs les plus courantes incluent la sous-estimation du temps de préparation des données, l’ignorance de la documentation de la lignée des données, l’ignorance de la variabilité des processus, la négligence de l’assignation de propriétaires de données et l’hypothèse que la qualité des données existante est suffisante pour l’IA. Ces erreurs conduisent généralement à des retards de projet, des coûts accrus et parfois à un échec complet du projet.
L’IA peut-elle fonctionner avec des données imparfaites, ou des données parfaites sont-elles requises ?
L’IA peut fonctionner avec des données imparfaites, mais le degré d’imperfection compte. De petites quantités de données manquantes ou bruyantes peuvent souvent être gérées par des techniques de nettoyage des données et une conception de modèle robuste. Cependant, des problèmes de qualité de données significatifs impacteront les performances du modèle et peuvent rendre l’IA impraticable. L’objectif n’est pas des données parfaites mais des données qui répondent aux seuils de qualité minimum pour votre cas d’utilisation spécifique.
Comment savoir si mon organisation est prête pour l’IA en termes de données ?
Votre organisation est prête pour l’IA en termes de données si vous avez des volumes suffisants de données pertinentes qui répondent aux seuils de qualité (précision, exhaustivité, cohérence), une propriété et une gouvernance des données claires, des processus standardisés qui génèrent des données cohérentes et l’infrastructure technique pour soutenir les charges de travail IA. Une évaluation formelle de la préparation des données peut vous aider à évaluer ces critères de manière systématique et identifier les lacunes à adresser.
