
Die KI-Datenbereitschaft bewertet, ob die Daten Ihrer Organisation die spezifischen Qualitäts-, Mengen- und Governance-Anforderungen erfüllen, die für eine erfolgreiche Implementierung der künstlichen Intelligenz erforderlich sind. Im Gegensatz zur traditionellen Datenanalyse verlangen KI-Systeme höhere Standards für Datenqualität, Vollständigkeit und Konsistenz, um zuverlässige Modelle zu trainieren und genaue Vorhersagen zu treffen. Organisationen, die die Datenbereitschaft vor KI-Projekten bewerten, reduzieren das Risiko des Projektversagens erheblich und vermeiden kostspielige Korrekturen mitten im Projekt.
Wichtige Erkenntnisse
- Nicht standardisierte Prozesse schaffen Datenqualitätsprobleme, die die KI-Modellleistung und Vorhersagegenauigkeit direkt beeinträchtigen
- Daten müssen spezifische Qualitätsschwellen einschließlich Genauigkeit, Vollständigkeit und Konsistenz vor der KI-Implementierung erfüllen, um Verzerrungen und Leistungsprobleme zu vermeiden
- Fehlende, falsche, fragmentierte oder eigentümerlose Daten führen zu erheblichen Geschäftsrisiken einschließlich verzerrter Modelle und schlechter Entscheidungsfindung
- Der Auditprozess und der Datenfluss vor KI-Projekten helfen, Engpässe, Governance-Lücken und Integrationsherausforderungen zu identifizieren
- Prioritätsmaßnahmen sollten sich auf Dateninventar, Governance-Einrichtung und Prozessstandardisierung mit klaren Zeitplänen konzentrieren
Was ist KI-Datenbereitschaft?
Die KI-Datenbereitschaft bezieht sich auf den Zustand der Dateninfrastruktur und -qualität Ihrer Organisation im Verhältnis zu den spezifischen Anforderungen von KI-Systemen. Während traditionelle Analysen bis zu einem gewissen Grad mit unvollkommenen Daten arbeiten können, erfordern KI-Modelle—insbesondere maschinelle Lernsysteme—höhere Standards für Datenqualität, Struktur und Governance. Die Datenbereitschaft umfasst nicht nur die technischen Aspekte der Datenspeicherung und -verarbeitung, sondern auch die organisatorischen Praktiken rund um Datenerfassung, Wartung und Governance, die sicherstellen, dass Daten für KI-Anwendungen zuverlässig und zugänglich bleiben.
Der Unterschied zwischen allgemeiner Datenqualität und KI-spezifischer Datenbereitschaft liegt in der Skala und Komplexität der Anforderungen. KI-Systeme benötigen typischerweise größere Datenvolumina, vielfältigere Datentypen und strengere Konsistenzstandards als traditionelle Analysen. Sie erfordern auch, dass Daten ordnungsgemäß gekennzeichnet, dokumentiert und verwaltet werden, um sicherzustellen, dass das Modelltraining zuverlässige Ergebnisse liefert. Organisationen, die die Bewertung der Datenbereitschaft überspringen, entdecken diese Anforderungen oft mitten im Projekt, was zu Verzögerungen, erhöhten Kosten und manchmal zum vollständigen Scheitern des Projekts führt.
Das Verständnis des breiteren KI-Bereitschaftsrahmens kann Organisationen helfen, ihre Gesamtbereitschaft über Daten hinaus zu bewerten.
Wie nicht standardisierte Prozesse die KI beeinflussen
Die Verbindung zwischen Prozessstandardisierung und KI-Leistung ist direkt und signifikant. Wenn Geschäftsprozesse an Standardisierung fehlen, werden die aus diesen Prozessen generierten Daten inkonsistent, was es für KI-Systeme schwierig macht, zuverlässige Muster zu lernen. Prozessvariabilität führt Rauschen in Trainingsdaten ein, was zu Modellen führen kann, die schlecht funktionieren oder inkonsistente Vorhersagen treffen. Wenn beispielsweise verschiedene Teams unterschiedliche Verfahren für die Kundendateneingabe befolgen, hat der resultierende Datensatz inkonsistente Formate, fehlende Werte und variable Qualität—alles dies beeinträchtigt die KI-Modellleistung.
Nicht standardisierte Datenpipelines schaffen zusätzliche Herausforderungen. Wenn Daten durch mehrere Systeme fließen, ohne konsistente Transformationsregeln, kann derselbe Datenpunkt an verschiedenen Stufen unterschiedliche Werte haben, was Verwirrung für KI-Systeme schafft. Dies ist besonders problematisch für maschinelle Lernmodelle, die auf konsistente Feature-Engineering angewiesen sind. Organisationen mit nicht standardisierten Prozessen verbringen oft übermäßige Zeit mit der Bereinigung und Normalisierung von Daten—Zeit, die besser für Modellentwicklung und -optimierung verwendet werden könnte. Die Kosten nicht standardisierter Datenpipelines erstrecken sich über den technischen Aufwand hinaus und umfassen die geschäftliche Auswirkung, da Entscheidungen auf der Grundlage inkonsistenter Daten zu schlechten Ergebnissen führen können.
Die Prozessvariabilität wirkt sich auch auf die Fähigkeit aus, KI-Systeme über die Zeit zu warten. Wenn die Prozesse, die Trainingsdaten generieren, ohne ordnungsgemäße Dokumentation und Versionskontrolle ändern, können die auf diesen Daten trainierten KI-Modelle weniger genau oder sogar obsolet werden. Deshalb ist Prozessstandardisierung nicht nur ein Datenqualitätsproblem, sondern eine grundlegende Anforderung für eine nachhaltige KI-Implementierung. Organisationen, die Prozessstandardisierung vor KI-Projekten angehen, schaffen eine stabilere Grundlage für langfristigen KI-Erfolg.
Datenqualitätsanforderungen für KI
Genauigkeit, Vollständigkeit und Konsistenz
KI-Systeme erfordern Daten, die über alle Quellen hinweg genau, vollständig und konsistent sind. Genauigkeit bedeutet, dass die Daten reale Werte korrekt darstellen ohne systematische Fehler oder Verzerrungen. Vollständigkeit stellt sicher, dass kritische Attribute für alle relevanten Datensätze vorhanden sind—fehlende Werte können das Modelltraining und die Vorhersagegenauigkeit erheblich beeinträchtigen. Konsistenz erfordert, dass Daten über verschiedene Systeme und Zeiträume hinweg dieselben Formate, Definitionen und Standards befolgen. Inkonsistente Daten schaffen Verwirrung für KI-Systeme und können zu Modellen führen, die falsche Muster lernen.
Der Schwellenwert für akzeptable Datenqualität variiert je nach Anwendungsfall, aber allgemeine Best Practices deuten darauf hin, mindestens 95% Genauigkeit in kritischen Feldern, weniger als 5% fehlende Werte für Schlüsselattribute und 100% Konsistenz in Datendefinitionen anzustreben. Organisationen sollten Datenqualitäts-Baselines vor KI-Projekten festlegen und Überwachung implementieren, um diese Standards während des gesamten KI-Lebenszyklus aufrechtzuerhalten. Datenqualitätsprobleme, die in traditionellen Analysen geringfügig erscheinen, können in KI-Systemen aufgrund der Skala und Komplexität des Modelltrainings zu großen Problemen werden.
Professionelle Datenanalysedienste können Organisationen helfen, ihre Datenqualität vor der KI-Implementierung zu bewerten und zu verbessern.
Bedarf an Datenvolumen und -vielfalt
KI-Systeme benötigen typischerweise größere Datenvolumina als traditionelle Analysen, um eine zuverlässige Leistung zu erzielen. Das genaue Volumen hängt von der Komplexität des Problems und der Art des KI-Ansatzes ab, aber maschinelle Lernmodelle benötigen oft Tausende oder Millionen von Datenpunkten, um effektiv zu generalisieren. Kleine Datensätze können zu Überanpassung führen, bei der Modelle auf Trainingsdaten gut, aber auf neuen Daten schlecht funktionieren. Organisationen sollten bewerten, ob sie über ausreichende historische Daten verfügen oder synthetische Daten generieren können, um Volumenanforderungen zu erfüllen.
Datenvielfalt ist ebenso wichtig. KI-Systeme profitieren von diversen Datenquellen, die verschiedene Aspekte des Problembereichs erfassen. Dies kann strukturierte Daten aus Datenbanken, unstrukturierten Text aus Dokumenten, Bilder, Audio oder Sensordaten je nach Anwendung umfassen. Die Fähigkeit, verschiedene Datentypen zu integrieren und zu verarbeiten, ist ein Schlüsselunterschied für erfolgreiche KI-Implementierungen. Organisationen sollten ihre Datenquellen inventarisieren und bewerten, ob sie ausreichende Vielfalt bieten, um robuste Modelle zu trainieren.
Anforderungen an Kennzeichnung und Annotation
Überwachte maschinelle Lernansätze erfordern gekennzeichnete Daten—Daten, bei denen die korrekte Ausgabe oder Klassifikation bekannt ist. Datenkennzeichnung und -annotation können zeitaufwendig und teuer sein, insbesondere für komplexe Aufgaben wie Bilderkennung oder natürliche Sprachverarbeitung. Organisationen müssen bewerten, ob sie über vorhandene gekennzeichnete Daten, Ressourcen zur Kennzeichnung neuer Daten oder die Fähigkeit verfügen, semi-überwachte oder unüberwachte Ansätze zu verwenden, die weniger Kennzeichnung erfordern.
Die Qualität der Kennzeichnungen ist ebenso wichtig wie die Qualität der Daten selbst. Inkonsistente oder falsche Kennzeichnungen trainieren Modelle, falsche Vorhersagen zu treffen. Organisationen sollten klare Kennzeichnungsrichtlinien festlegen, Kennzeichner in diesen Richtlinien schulen und Qualitätskontrollprozesse implementieren, um die Kennzeichnungsgenauigkeit sicherzustellen. Für Hochrisikoanwendungen können mehrere unabhängige Kennzeichner erforderlich sein, um Konsens sicherzustellen und Verzerrungen zu reduzieren.
Datenfrische und Aktualität
KI-Systeme benötigen aktuelle Daten, um relevant und genau zu bleiben. Die Anforderungen an Datenfrische variieren je nach Anwendung—einige Anwendungsfälle können mit leicht veralteten Daten arbeiten, während andere Echtzeit- oder Nahechtzeit-Aktualisierungen erfordern. Organisationen sollten ihre Datenaktualisierungsfrequenz bewerten und feststellen, ob sie den Bedürfnissen ihrer KI-Anwendungen entspricht. Für zeitkritische Anwendungen wie Betrugserkennung oder vorausschauende Wartung ist Datenfrische kritisch und kann Investitionen in Echtzeit-Datenpipelines erfordern.
Datenaktualität bezieht sich auch auf die Fähigkeit, bei Bedarf auf Daten zuzugreifen. Wenn Daten verfügbar, aber aufgrund von Systemeinschränkungen, Berechtigungen oder technischen Einschränkungen schwer zugänglich sind, existieren sie effektiv nicht für KI-Zwecke. Organisationen sollten Datenzugänglichkeit und Latenz bewerten, um sicherzustellen, dass KI-Systeme die benötigten Daten erhalten, wenn sie sie benötigen.

Risiken schlechter Datenqualität
Risiken fehlender Daten
Fehlende Daten führen zu mehreren Risiken für KI-Systeme. Wenn kritische Attribute fehlen, können Modelle falsche Muster lernen oder verzerrte Vorhersagen treffen. Wenn beispielsweise Kundendemografiedaten für bestimmte Segmente fehlen, kann ein auf diesen Daten trainiertes Modell für diese Segmente schlecht funktionieren. Fehlende Daten können auch zu Überanpassung führen, wenn das Modell lernt, sich auf Muster zu verlassen, die nur in den vollständigen Datensätzen existieren, was seine Generalisierungsfähigkeit verringert.
Die geschäftliche Auswirkung fehlender Daten umfasst schlechte Entscheidungsfindung, reduzierte Modellgenauigkeit und potenzielle Verzerrungen gegen unterrepräsentierte Gruppen. Organisationen, die fehlende Daten vor der KI-Implementierung nicht angehen, können diese Probleme erst entdecken, nachdem Modelle bereitgestellt wurden, was kostspieliges Retraining erfordert und potenziell Geschäftsbeziehungen oder den Ruf schädigt.
Risiken falscher Daten
Falsche Daten—Daten, die Fehler, Ungenauigkeiten oder Inkonsistenzen enthalten—stellen schwerwiegende Risiken für KI-Systeme dar. Auf falschen Daten trainierte Modelle lernen falsche Muster, was zu systematisch falschen Vorhersagen führt. Dies ist besonders gefährlich in Hochrisikoanwendungen wie Gesundheitswesen, Finanzen oder sicherheitskritischen Systemen, wo falsche Vorhersagen schwerwiegende Folgen haben können.
Die Auswirkung falscher Daten erstreckt sich über die Modellleistung hinaus auf das geschäftliche Vertrauen. Wenn Stakeholder feststellen, dass KI-Systeme Entscheidungen auf der Grundlage falscher Daten treffen, können sie das Vertrauen in die gesamte KI-Initiative verlieren. Organisationen sollten Datenvalidierungsprozesse, Fehlererkennungsmechanismen und regelmäßige Audits implementieren, um falsche Daten zu identifizieren und zu korrigieren, bevor sie KI-Systeme beeinflussen.
Risiken fragmentierter Daten
Fragmentierte Daten—Daten, die in Silos über verschiedene Systeme ohne Integration existieren—begrenzen die Fähigkeit von KI-Systemen, umfassende Muster zu lernen. Wenn Daten fragmentiert sind, sehen KI-Modelle nur Teilbilder des Problembereichs, was zu unvollständigen Erkenntnissen und suboptimalen Entscheidungen führt. Fragmentierung macht es auch schwierig, Datenkonsistenz und Governance in der gesamten Organisation aufrechtzuerhalten.
Die Geschäftsrisiken fragmentierter Daten umfassen verpasste Chancen für funktionsübergreifende Erkenntnisse, inkonsistente Entscheidungsfindung zwischen Abteilungen und erhöhte Komplexität im Datenmanagement. Organisationen sollten ihre Datenlandschaft bewerten und Integrationsmöglichkeiten vor KI-Projekten identifizieren, um sicherzustellen, dass Modelle Zugriff auf umfassende, einheitliche Daten haben.
Risiken eigentümerloser Daten
Eigentümerlose Daten—Daten ohne klare Eigentum oder Verantwortlichkeit—schaffen Wartungs- und Governance-Probleme. Wenn niemand für Datenqualität, Genauigkeit und Aktualisierungen verantwortlich ist, neigen Daten dazu, über die Zeit zu degradieren. Diese Degradation kann die KI-Modellleistung erheblich beeinträchtigen, insbesondere für Modelle, die kontinuierliches Training mit frischen Daten erfordern.
Eigentümerlose Daten schaffen auch Governance-Herausforderungen. Ohne klares Eigentum ist es schwierig, Datenzugriffsrichtlinien, Sicherheitskontrollen und Compliance-Maßnahmen festzulegen. Organisationen sollten Dateneigentümer für kritische Datensätze zuweisen und klare Verantwortlichkeiten für Datenwartung, Qualitätsüberwachung und Governance festlegen. Diese Eigentumsstruktur ist für nachhaltige KI-Operationen unerlässlich.
Wie man Prozess und Datenfluss auditieren
Prozess-Audit-Rahmen
Das Auditing von Geschäftsprozessen vor der KI-Implementierung hilft, Variabilität, Engpässe und Standardisierungsmöglichkeiten zu identifizieren. Der Prozess-Audit-Rahmen sollte aktuelle Workflows abbilden, Entscheidungspunkte dokumentieren und Prozessvariationen über verschiedene Teams oder Standorte hinweg bewerten. Diese Abbildung zeigt, wo Prozesse konsistent und wo sie unterschiedlich sind, und bietet Einblick in potenzielle Datenqualitätsprobleme.
Das Audit sollte auch Automatisierungsmöglichkeiten bewerten. Hoch standardisierte und regelbasierte Prozesse sind gute Kandidaten für KI-Augmentation, während hoch variable Prozesse möglicherweise Standardisierung erfordern, bevor KI effektiv angewendet werden kann. Organisationen sollten aktuelle Prozessleistungsmetriken dokumentieren, um Baselines für die Messung der KI-Auswirkung später festzulegen.
Datenfluss-Audit
Das Datenfluss-Audit verfolgt, wie Daten durch Systeme von der Erstellung bis zum Verbrauch fließen. Dieses Audit sollte Datenquellen, Transformationsschritte, Speicherorte und Zugriffsmuster identifizieren. Das Ziel ist, den vollständigen Datenlebenszyklus zu verstehen und Punkte zu identifizieren, an denen Datenqualität degradieren könnte oder wo Engpässe auftreten.
Wichtige Aspekte des Datenfluss-Audits umfassen die Abbildung der Datenherkunft (den Pfad, den Daten von der Quelle zum Ziel nehmen), die Identifizierung von Datentransformationsregeln und die Bewertung der Datenintegrität in jeder Phase. Das Audit sollte auch Datenzugriffskontrollen und Sicherheitsmaßnahmen bewerten, um sicherzustellen, dass KI-Systeme angemessenen Zugriff auf benötigte Daten haben, während die Compliance mit Datenschutz- und Sicherheitsanforderungen aufrechterhalten wird.
Der KI-Risikomanagement-Rahmen des NIST bietet Leitlinien für Daten-Governance- und Sicherheitspraktiken für KI-Systeme.
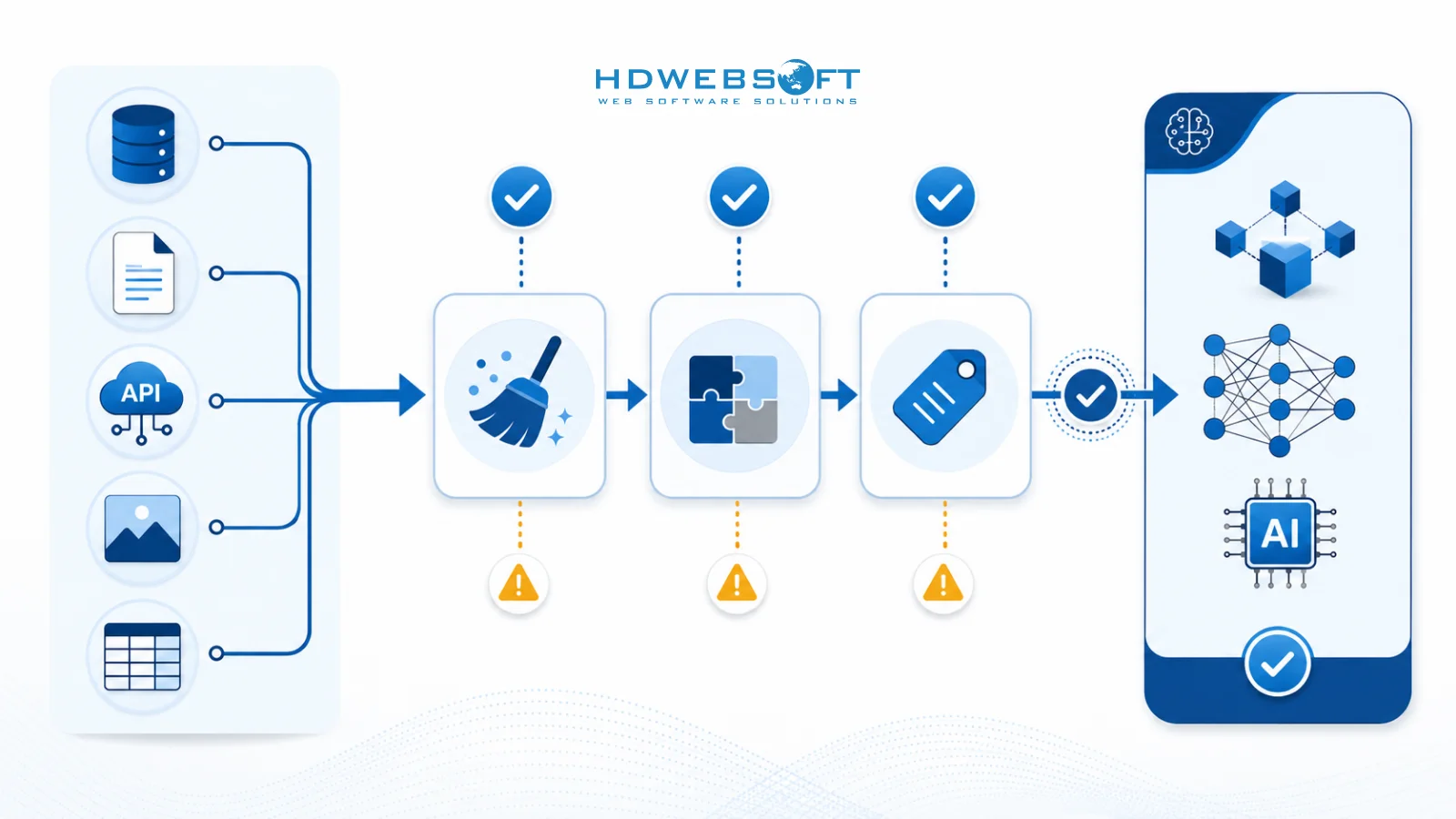
Audit-Checkliste
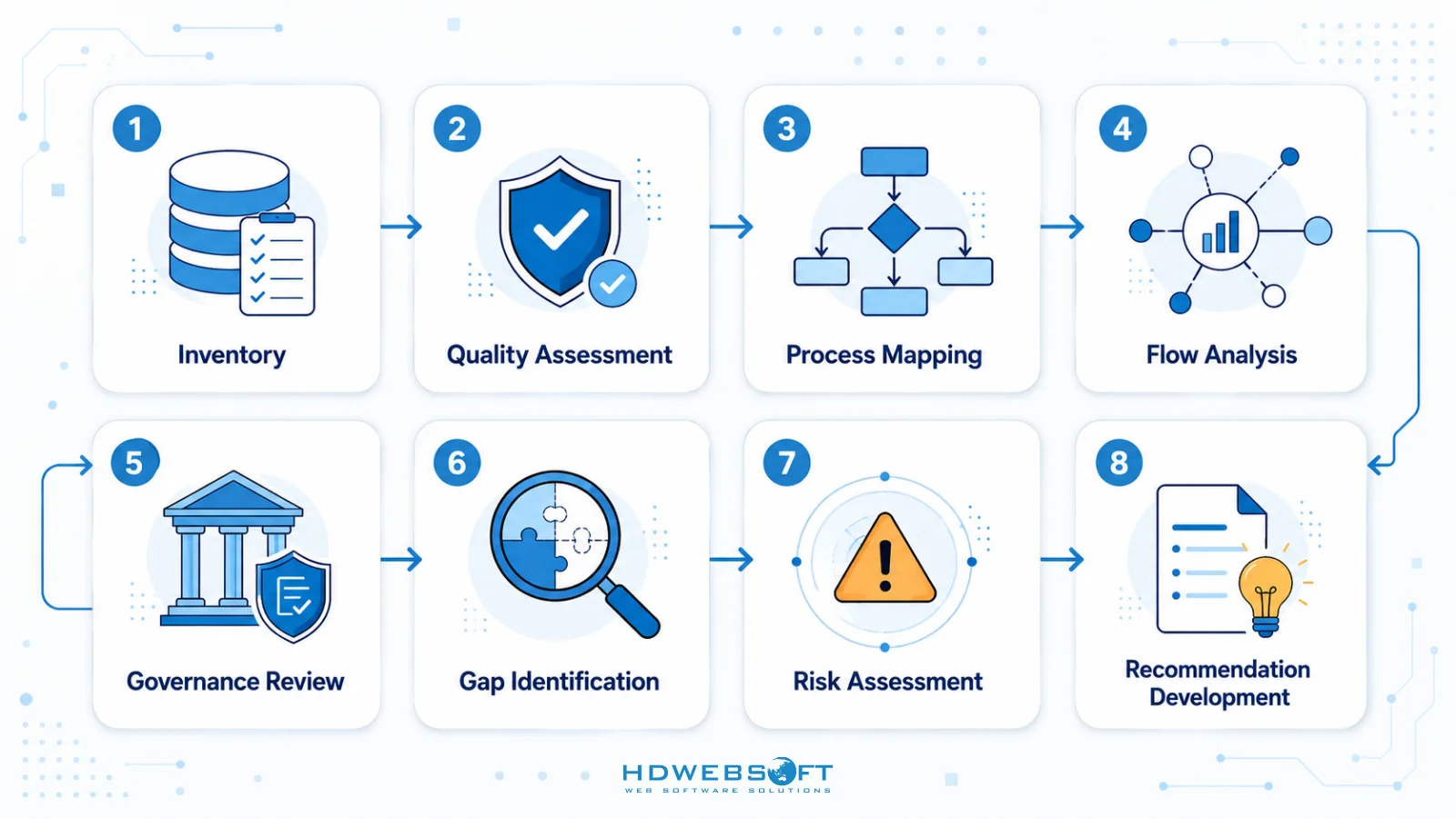
Ein umfassendes Datenbereitschafts-Audit sollte die folgenden Schritte umfassen:
- Dateninventar: Katalogisieren aller Datenquellen, Typen, Volumina und Standorte
- Qualitätsbewertung: Bewertung von Genauigkeit, Vollständigkeit, Konsistenz und Frische
- Prozessabbildung: Dokumentation von Geschäftsprozessen, die Daten generieren oder verwenden
- Flussanalyse: Verfolgung der Datenbewegung durch Systeme und Transformationen
- Governance-Überprüfung: Bewertung von Dateneigentum, Zugriffskontrollen und Compliance
- Lückenidentifikation: Vergleich des aktuellen Zustands mit KI-Anforderungen
- Risikobewertung: Identifizierung potenzieller datenbezogener Risiken für KI-Projekte
- Empfehlungsentwicklung: Vorschlag spezifischer Maßnahmen zur Adressierung von Lücken und Risiken
Organisationen sollten diese Checkliste als strukturierten Ansatz zur Datenbereitschaftsbewertung verwenden, um eine umfassende Abdeckung aller kritischen Aspekte sicherzustellen.
Prioritätsmaßnahmen zur Vorbereitung von Daten und Workflow
Sofortige Maßnahmen (Woche 1-2)
Die ersten zwei Wochen sollten sich auf grundlegende Aktivitäten konzentrieren, die schnelle Gewinne bieten und Baselines festlegen. Beginnen Sie mit einem umfassenden Dateninventar, um zu verstehen, welche Daten existieren, wo sie gespeichert sind und wer sie besitzt. Dieses Inventar sollte Datenquellen, Volumina, Formate und Qualitätsbewertungen umfassen. Identifizieren Sie gleichzeitig die kritischsten Datenquellen für Ihre geplanten KI-Initiativen und priorisieren Sie sie für sofortige Aufmerksamkeit.
Legen Sie Datenqualitäts-Baselines fest, indem Sie aktuelle Genauigkeits-, Vollständigkeits- und Konsistenzniveaus messen. Diese Baselines helfen Ihnen, die Verbesserung über die Zeit zu messen und realistische Erwartungen für KI-Projektzeitpläne festzulegen. Beginnen Sie mit der Dokumentation wichtiger Geschäftsprozesse, die kritische Daten generieren oder verwenden, mit Fokus auf Bereiche mit hoher Variabilität oder bekannten Qualitätsproblemen.
Kurzfristige Maßnahmen (Monat 1-2)
Die ersten zwei Monate sollten die kritischsten Lücken adressieren, die im Audit identifiziert wurden. Implementieren Sie Datenbereinigung und -standardisierung für priorisierte Datenquellen mit Fokus auf Genauigkeit, Vollständigkeit und Konsistenz. Richten Sie ein grundlegendes Daten-Governance-Framework ein, indem Sie Dateneigentümer zuweisen, Zugriffsp Richtlinien definieren und Datenstandards dokumentieren.
Beginnen Sie mit Prozessstandardisierungsinitiativen für Workflows, die kritische Daten generieren. Dies kann die Erstellung von Standardarbeitsanweisungen, die Implementierung von Validierungsregeln oder das Training von Teams auf konsistente Praktiken umfassen. Richten Sie automatisierte Datenqualitätsüberwachung ein, wo möglich, um Probleme frühzeitig zu erkennen und die vorgenommenen Verbesserungen aufrechtzuerhalten.
Mittelfristige Maßnahmen (Monat 3-6)
Der mittelfristige Fokus sollte auf dem Aufbau nachhaltiger Fähigkeiten und der Skalierung von Verbesserungen liegen. Implementieren Sie automatisierte Datenqualitätsüberwachung über alle kritischen Datenquellen hinweg mit Warnungen für Qualitätsdegradation. Optimieren Sie Datenpipelines, um manuellen Aufwand zu reduzieren und Zuverlässigkeit zu verbessern. Dies kann Investitionen in Datenintegrationstools, die Implementierung von Masterdatenmanagement oder die Entwicklung automatisierter Bereinigungs- und Validierungsprozesse umfassen.
Implementieren Sie Prozessautomatisierung, wo Standardisierung erreicht wurde, unter Verwendung von Tools wie Robotic Process Automation (RPA) oder Workflow-Automatisierung, um menschliche Fehler zu reduzieren und Konsistenz zu verbessern. Richten Sie kontinuierliche Verbesserungsprozesse ein, um regelmäßig Datenqualitätsmetriken, Prozessleistung und KI-Modellausgaben zu überprüfen und Anpassungen nach Bedarf vorzunehmen. Dies schafft eine Feedback-Schleife, die sicherstellt, dass Datenbereitschaft über die Zeit verbessert wird, anstatt zu degradieren.
KI-Datenbereitschafts-Checkliste
Verwenden Sie diese Checkliste, um die Datenbereitschaft Ihrer Organisation vor der KI-Implementierung zu bewerten:
Dateninventar
- Alle kritischen Datenquellen identifiziert und katalogisiert
- Datenvolumina und -vielfalt gegen KI-Anforderungen bewertet
- Dateneigentümer für alle kritischen Datensätze zugewiesen
- Datenzugriffsmuster dokumentiert
Datenqualität
- Genauigkeit gemessen und erfüllt Mindestschwellen (95% oder mehr für kritische Felder)
- Vollständigkeit bewertet mit weniger als 5% fehlenden Werten für Schlüsselattribute
- Konsistenz über Systeme und Zeiträume hinweg verifiziert
- Datenfrische-Anforderungen definiert und erfüllt
Prozessstandardisierung
- Wichtige Geschäftsprozesse dokumentiert
- Prozessvariabilität bewertet und quantifiziert
- Standardarbeitsanweisungen erstellt
- Automatisierungsmöglichkeiten identifiziert
Daten-Governance
- Daten-Governance-Framework eingerichtet
- Zugriffskontrollen und Sicherheitsrichtlinien implementiert
- Datenqualitätsüberwachung eingerichtet
- Compliance-Anforderungen adressiert
Technische Bereitschaft
- Dateninfrastruktur für KI-Workloads bewertet
- Integrationsfähigkeiten mit bestehenden Systemen verifiziert
- Datenpipeline-Architektur entworfen
- Skalierbarkeitsüberlegungen adressiert
Häufige Datenbereitschaftsfehler
Organisationen unterschätzen oft die Zeit und den Aufwand, der für Datenvorbereitung erforderlich ist, und nehmen an, dass es ein schneller Schritt vor der “eigentlichen Arbeit” der KI-Entwicklung ist. In der Realität verbraucht Datenvorbereitung typischerweise 60-80% der Zeit in KI-Projekten. Laut Industrieforschung führt das Überspringen einer gründlichen Datenbewertung, um Zeit zu sparen, normalerweise zu längeren Gesamtzeitplänen, da Probleme mitten im Projekt entdeckt werden.
Ein weiterer häufiger Fehler ist die Vernachlässigung der Datenherkunftsdokumentation. Ohne klare Dokumentation, woher Daten kommen, wie sie transformiert werden und welche Annahmen in sie eingebaut sind, haben Organisationen Schwierigkeiten, Probleme zu beheben, Ergebnisse zu reproduzieren oder Modelle über die Zeit zu warten. Datenherkunft ist für Transparenz, Debugging und regulatorische Compliance unerlässlich.
Das Ignorieren der Prozessvariabilität ist ebenfalls ein häufiger Fehler. Organisationen nehmen an, dass ihre Prozesse konsistenter sind, als sie tatsächlich sind, was zu unerwarteten Datenqualitätsproblemen führt. Prozessstandardisierung sollte früh angegangen werden, da sie oft schwieriger zu beheben ist als technische Datenprobleme.
Schließlich übersehen viele Organisationen die Bedeutung der Dateneigentumszuweisung. Ohne klares Eigentum degradiert Datenqualität über die Zeit, und niemand ist für die Aufrechterhaltung der für KI-Erfolg erforderlichen Standards verantwortlich. Die Zuweisung von Dateneigentümern und die Festlegung klarer Verantwortlichkeiten ist ein grundlegender Schritt, der nicht übersprungen werden sollte.
Fazit
KI-Datenbereitschaft ist nicht optional—sie ist eine Voraussetzung für eine erfolgreiche KI-Implementierung. Organisationen, die Zeit in die Bewertung und Verbesserung ihrer Datenbereitschaft vor KI-Projekten investieren, reduzieren das Risiko des Scheiterns erheblich und verbessern die Wahrscheinlichkeit, bedeutenden Geschäftswert zu erzielen. Die Investition in Datenvorbereitung zahlt sich durch schnellere Entwicklungszyklen, genauere Modelle und nachhaltige KI-Operationen aus.
Die Reise zur Datenbereitschaft erfordert Aufmerksamkeit sowohl für technische als auch organisatorische Aspekte. Technische Verbesserungen wie Datenbereinigung, Integration und Infrastruktur sind notwendig, aber nicht ausreichend. Organisatorische Veränderungen wie Prozessstandardisierung, Governance-Frameworks und Dateneigentumszuweisung sind ebenso wichtig für langfristigen Erfolg.
Wenn Sie KI-Initiativen planen, beginnen Sie mit einer umfassenden Datenbereitschaftsbewertung. HDWEBSOFT kann Ihnen helfen, Ihre aktuelle Datenlandschaft zu bewerten, Lücken zu identifizieren und eine Roadmap zur Vorbereitung Ihrer Daten für KI-Erfolg zu entwickeln. Unsere KI-Entwicklungsdienste umfassen Datenbewertung, Governance-Implementierung und Pipeline-Entwicklung, um sicherzustellen, dass Ihre KI-Initiativen die solide Grundlage haben, die sie benötigen.
FAQ
Was ist der Unterschied zwischen allgemeiner Datenqualität und KI-Datenbereitschaft?
Allgemeine Datenqualität konzentriert sich darauf, ob Daten genau und für traditionelle Analysen und Berichte verwendbar sind. KI-Datenbereitschaft erfordert höhere Standards—größere Volumina, vielfältigere Typen, strengere Konsistenz und ordnungsgemäße Kennzeichnung für maschinelles Lernen. KI-Systeme benötigen auch Daten-Governance, Datenherkunftsdokumentation und kontinuierliche Qualitätsüberwachung, die für grundlegende Analysen möglicherweise nicht erforderlich sind.
Wie lange dauert es, Daten für die KI-Implementierung vorzubereiten?
Der Zeitplan variiert je nach dem aktuellen Zustand Ihrer Daten und der Komplexität Ihrer KI-Anforderungen. Einfache Anwendungsfälle mit guten vorhandenen Daten benötigen möglicherweise 4-6 Wochen Vorbereitung. Komplexe Projekte mit erheblichen Datenqualitätsproblemen oder Integrationsherausforderungen können 3-6 Monate erfordern. Organisationen sollten Datenvorbereitungszeit in ihre KI-Projektplanung einbeziehen, anstatt sie als Nachgedanke zu behandeln.
Was sind die häufigsten Datenbereitschaftsfehler, die Organisationen begehen?
Die häufigsten Fehler umfassen die Unterschätzung der Datenvorbereitungszeit, das Überspringen der Datenherkunftsdokumentation, das Ignorieren der Prozessvariabilität, die Vernachlässigung der Dateneigentumszuweisung und die Annahme, dass die vorhandene Datenqualität für KI ausreichend ist. Diese Fehler führen normalerweise zu Projektverzögerungen, erhöhten Kosten und manchmal zum vollständigen Scheitern des Projekts.
Kann KI mit unvollkommenen Daten arbeiten, oder sind perfekte Daten erforderlich?
KI kann mit unvollkommenen Daten arbeiten, aber der Grad der Unvollkommenheit matters. Kleine Mengen fehlender oder verrauschter Daten können oft durch Datenbereinigungstechniken und robustes Modelldesign bewältigt werden. Signifikante Datenqualitätsprobleme wirken sich jedoch auf die Modellleistung aus und können KI unpraktisch machen. Das Ziel ist nicht perfekte Daten, sondern Daten, die Mindestqualitätsschwellen für Ihren spezifischen Anwendungsfall erfüllen.
Wie weiß ich, ob meine organisation für KI in Bezug auf Daten bereit ist?
Ihre Organisation ist für KI in Bezug auf Daten bereit, wenn Sie über ausreichende Volumina relevanter Daten verfügen, die Qualitätsschwellen (Genauigkeit, Vollständigkeit, Konsistenz) erfüllen, klares Dateneigentum und Governance haben, standardisierte Prozesse, die konsistente Daten generieren, und die technische Infrastruktur zur Unterstützung von KI-Workloads. Eine formale Datenbereitschaftsbewertung kann Ihnen helfen, diese Kriterien systematisch zu bewerten und Lücken zu identifizieren, die adressiert werden müssen.
