
NERモデル(Named Entity Recognition model、固有表現抽出モデル)は、テキスト内のエンティティを識別し分類する NLP の中核技術です。非構造化データが指数関数的に増加する現在、意味のある情報を抽出することは企業にとって不可欠になっています。テキストデータを分析し整理するこの能力により、NER はさまざまな業界で重要な技術になっています。
この記事では、固有表現抽出とは何か、その概念を簡単な例で説明します。さらに、NER の代表的な use cases と、NERモデルがどのように機能するのかを解説します。
固有表現抽出とは?

固有表現抽出は、テキスト内の特定のエンティティを識別し分類する自然言語処理の技術です。これらのエンティティには、人名、組織名、場所、日付、数値などが含まれます。
当然ながら、NER はこの技術の中心にあり、意味のあるインサイトを抽出することで、非構造化テキストデータを構造化できるようにします。NERモデルは、チャットボット、感情分析、検索エンジンなど、多くのアプリケーションの基盤となっています。最近のレポートによると、世界の NLP 市場は2030年までに $1,568億 に達すると予測されています。NER のようなツールが普及することで、AI と ML はさまざまな領域でさらに明るい未来を切り開くでしょう。
NERモデルの目的
Named Entity Recognition モデルの主な目的は、分析のために生のテキストを構造化された形式へ変換することです。重要な情報を分類することで、企業は膨大なデータセットから実用的なインサイトを抽出できます。その結果、効率的な意思決定が可能になり、医療、金融、カスタマーサービスなどの業界での応用を支えます。
NERモデルの主要コンセプト

NER の背後では、言語を効果的に理解・処理するために、いくつかの重要な概念と技術が使われています。ここからは、それぞれの要素を詳しく見ていきましょう。
POS Tagging
品詞タグ付け、つまり POS tagging は、NERモデルを構築するうえで基礎となるステップの一つです。これは、文中の各単語に対して、名詞、動詞、形容詞、副詞などの文法的役割を付与する処理です。たとえば “The doctor visited Paris,” という文では、モデルは doctor を名詞、visited を動詞としてタグ付けします。
このタグ付けは、モデルが 文中で各単語が果たす役割を理解する ため、NER にとって重要です。特に、固有名詞は人名、場所、組織名を示す手がかりになることがよくあります。その意味で、POS tagging は文脈を提供し、モデルがエンティティを分類する際により正確な予測を行えるようにします。
要するに、このタグ付け処理によって、モデルはエンティティである可能性の高い単語に焦点を絞り、精度を高めることができます。
Corpus
Corpus とは、基本的に Named Entity Recognition モデルを訓練するために使用される大規模なテキスト集合です。このデータセットには、名前、場所、日付などをマークしたラベル付きの例が付与されています。NERモデルの学習 corpus では、“Apple Inc. is based in California” という文において、Apple Inc. は組織、California は場所として示されます。
Corpus の品質と多様性は、モデルの性能に直接影響します。バランスの取れた corpus は、フォーマルなビジネス文書からカジュアルな SNS 投稿まで、NER がさまざまな種類のテキストに対応するうえで役立ちます。モデルは corpus からパターンを学習することで、未知のデータを効果的に処理できるよう理解を一般化します。
Chunking
次に紹介するのは chunking です。これは shallow parsing とも呼ばれ、文をより小さく扱いやすい句や chunk に分割する処理です。たとえば “The quick brown fox jumped over the lazy dog” という文は、“The quick brown fox” や “over the lazy dog.” のような句に分けられます。
NER の文脈では、chunking は単語をまとめてエンティティを識別するために役立ちます。この NERモデルの概念は、複数語からなるエンティティにとって特に重要です。そのような場合、単語同士の関係を理解することが正確な認識に不可欠です。
Word Embeddings
Word embeddings は、多次元空間における単語の数学的表現です。単語を数値形式で高度に表現し、その意味や文脈上の関係を捉えます。
NER では、Word2Vec、GloVe、または BERT のような transformer ベースのモデルが生成する embedding が重要な役割を担います。具体的には、これらの embedding により、モデルは 単語の文字通りの意味と、文中の他の単語との関係の両方を理解できます。この能力は、曖昧または複雑な文脈でエンティティを区別する際に特に重要です。このような深い分析がなければ、表面的なアプローチでは正確な結果を得られない場合があります。
NERの例
NERモデルをテストするための文として、次の例を考えてみましょう。“Tesla announced that Elon Musk plans to open a new factory in Austin, Texas, by the end of 2025.”

displaCy Named Entity Visualizer を使って、この文に NERモデルを適用した例です。
この文では、次のように分類されます。
- “Tesla” は ORG とタグ付けされ、組織または企業を表します。
- “Elon Musk” は PERSON とラベル付けされ、人名を指すエンティティであることを示します。
- “Austin” と “Texas” は GPE に分類されます。これは Geopolitical Entity の略で、特定の都市や地域を識別します。
- “2025” は DATE として認識され、時間に関するエンティティを表します。
つまり、このような固有表現をテキストから自動的に抽出し分類したい場合、NER は採用すべき技術です。本質的には、重要な要素とそれらの関係を識別することで、コンピューターがテキストの意味を理解できるようにします。
NERモデルの主な活用例
Named Entity Recognition モデルは、さまざまな業界でイノベーションを促進してきました。非構造化テキスト内のエンティティを識別・分類することで、企業はプロセスを効率化し、インサイトを高め、データドリブンな意思決定を行えます。ここでは、さまざまな領域における NERモデルの主な用途を見ていきましょう。
情報検索
NER の主な用途の一つは情報検索です。膨大なデータが毎日生成される時代において、非構造化テキストから関連情報を取り出すことは重要です。具体的には、Named Entity Recognition は、大規模データセットから名前、場所、日付、特定の用語などのエンティティを抽出することに優れています。その結果、関連コンテンツのインデックス化と検索が容易になります。

NERモデルは、大量のデータから情報を検索する際に特に有用です。
法律業界を例に考えてみましょう。Named Entity Recognition モデルは、法的文書から事件番号、訴訟当事者の名前、判決の詳細などを抽出できます。その結果、判例調査のプロセスが高速化されます。同様に、学術分野では、研究者が科学論文や研究データセットから重要情報を取り出すために NER を使用し、時間と労力を節約しています。
データ入力の自動化
手作業でのデータ入力は時間がかかるだけでなく、ミスも起こりやすい作業です。この技術は、テキスト内の重要情報を識別し、構造化形式へ分類することで、そのプロセスを自動化します。特に、NERモデルは医療のような業界で有用です。患者ケアにおいて正確なデータ記録が不可欠だからです。
たとえば、医療機関は NER を使い、臨床記録から患者名、病状、処方された治療を抽出できます。このデータは電子健康記録(EHR)にスムーズに入力され、管理負担を減らし、精度を高めます。同様に、Named Entity Recognition モデルは金融分野における AI の応用例にもなります。具体的には、請求書や銀行明細から取引詳細、口座番号、日付を自動抽出できます。
感情分析の高度化
感情分析の目的は、テキストに表れる感情や意見を測定することです。これは marketing やカスタマーサービスでよく使われる AI ツールです。従来の感情分析が全体的な感情スコアを提供する一方で、NER技術を統合することにより 粒度が高まります。NERモデルは、製品名、サービスへの言及、競合他社など、テキスト内の特定のエンティティを識別します。これにより、組織は顧客が何について話しているのか、そしてそれについてどう感じているのかを正確に把握できます。
例を見てみましょう。顧客レビューに “I loved the camera on the new Phone X, but the battery life is disappointing,” と書かれている場合、モデルは Phone X を製品として識別できます。さらに、そのカメラとバッテリー寿命に関連する感情を個別に分けることができます。この詳細さは、提供価値や顧客体験の改善を目指す企業にとって非常に重要です。
小売やホスピタリティのような業界では、顧客フィードバックが鍵になります。そのため、Named Entity Recognition モデルは、戦略改善と顧客満足度向上につながる実用的なインサイトを生み出します。
NERモデルの仕組み
NER は基本的に、次の2つの主要ステップで構成されます。
- テキスト内のエンティティを検出する。
- それらのエンティティを特定のカテゴリへ分類する。
もう少し詳しく見ていきましょう。
エンティティ検出
NERモデルのプロセスにおける基礎ステップはエンティティ検出です。これは mention detection または entity spotting とも呼ばれます。関心対象のエンティティを表す可能性があるテキスト断片を識別する処理です。このフェーズは、以降の分析対象を絞り込むために重要です。その結果、関連性のある部分だけが次の段階へ進みます。

NERモデルの最初のステップである entity spotting は、関連するエンティティを検出し 示します。
Tokenization
エンティティ検出の中心にあるのが tokenization です。これは、文または文書をより小さな構成要素である token に分解するプロセスです。Token は通常単語ですが、句読点や記号を含むこともあります。たとえば “OpenAI created ChatGPT in 2023,” という文では、token は OpenAI、created、ChatGPT、2023 になります。
テキストを扱いやすい単位へ分割することで、tokenization はその後の処理の土台を作ります。その結果、Named Entity Recognition モデルは、周囲のテキストから特定のエンティティを切り出せるようになります。
特徴抽出
Token が識別されると、NERモデルはそれらから意味のある特徴を抽出し、エンティティである可能性を判断します。このステップでは、次の点を調べます。
- 形態的特徴: 語根、接頭辞、接尾辞などの単語構造を分析し、run と running のような変化形を識別するのに役立ちます。
- 構文的特徴: 文中の単語同士の関係に注目します。特に、動詞の後に続く名詞を潜在的なエンティティとして識別するような処理です。
- 意味的特徴: 文脈における単語の広い意味を捉えます。たとえば bank という単語は、文によって金融機関を指す場合も、川岸を指す場合もあります。
これらの特徴を利用することで、NER は意味のあるエンティティを見落とさず、同時に無関係なものをフィルタリングできます。
エンティティ分類
次のステップはエンティティ分類です。ここでは、検出されたエンティティが、その文脈と重要性に基づいて事前定義されたカテゴリに割り当てられます。このフェーズは、生のテキストを構造化されたインサイトへ変換するために不可欠です。
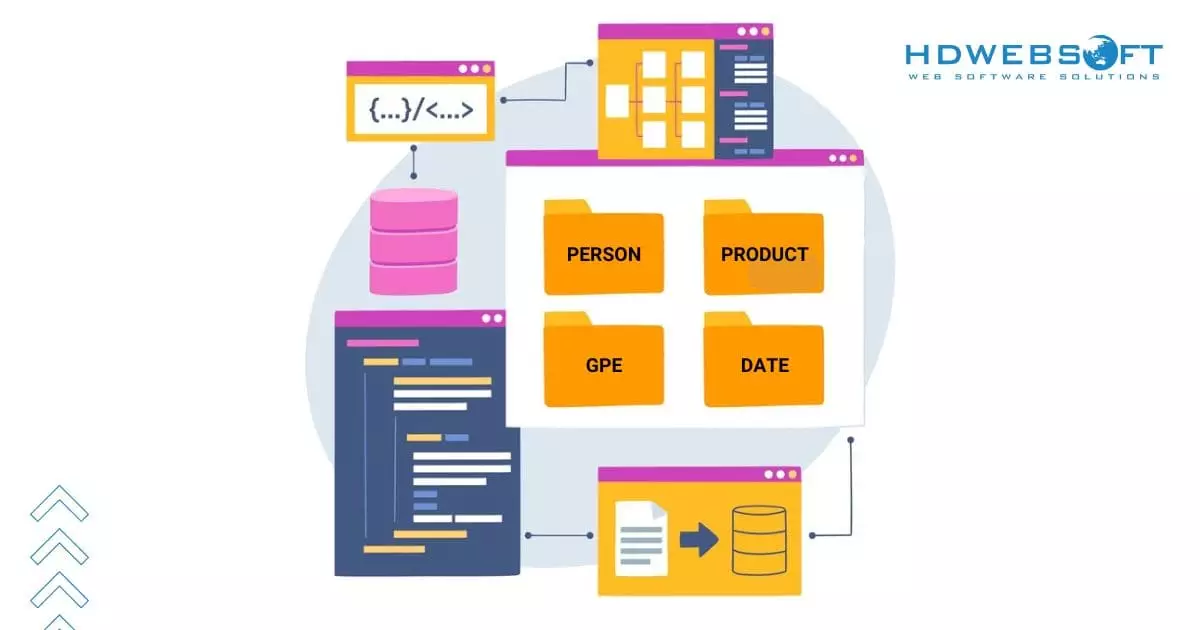
次のステップは、検出されたエンティティを所定のカテゴリに分類することです。
文脈理解
NERモデルで効果的にエンティティを分類するには、テキストの文脈をきめ細かく理解する必要があります。たとえば “Amazon delivers goods worldwide,” という文では、Amazon は組織として分類されます。一方、“The Amazon rainforest is vast,” では、同じ単語が場所を表します。
これを実現するため、モデルは言語分析と machine learning 技術を組み合わせて利用します。主なアプローチは次のとおりです。
- ルールベースのアプローチ: 大文字使用や特定の単語配置など、事前定義されたルールやパターンによってエンティティを分類します。
- 統計モデル: アルゴリズムがアノテーション済みデータセット内のパターンを分析し、エンティティのカテゴリを予測します。
- Deep Learning モデル: BERT のような高度なアーキテクチャは word embeddings を使ってより深い文脈的意味を捉え、分類プロセスを改善します。
曖昧性への対応
自然言語には、エンティティ分類を難しくする曖昧性がよく含まれます。たとえば “Spring arrives in March,” では Spring は季節を指しますが、“Spring Technologies launched a new app,” では組織名です。このような曖昧性を解決するには、多様で包括的なデータセットで訓練された高度なモデルが必要です。
エンティティ検出と分類をスムーズに統合することで、NERモデルは非構造化データを実用的なインサイトへ変換します。そのため、さまざまな業界やアプリケーションで効率化を推進します。
関連記事: AI Text Analysis はビジネスでどのように使われるのか?
NERモデルの課題
Named Entity Recognition 技術は非常に価値があることを証明していますが、課題がないわけではありません。これらの障害は、人間の言語の複雑さと、技術そのものの限界に起因することが多いです。ここでは、モデルが直面する主な課題を見ていきましょう。
曖昧性
まず、曖昧性は NER における最も大きなハードルの一つです。自然言語の単語やフレーズは複数の意味を持つことが多く、ある文脈でどの意味が当てはまるのかを判断することは難しい場合があります。
そのため、この問題はエンティティの識別と分類を複雑にします。モデルは限られた情報から正しい意味を推測しなければならないからです。さらに曖昧性は、特に非常にニュアンスの多いテキストや専門領域のテキストで、エラーの可能性を高めます。
文脈依存性
言語は文脈に強く依存しており、これは NERモデルに別の複雑さをもたらします。エンティティの意味や分類は、多くの場合、周囲の単語やフレーズに依存します。
考えてみてください。ある状況でエンティティである用語が、別の状況では同じ重要性を持たないことがあります。このように文脈上の手がかりへ依存するため、モデルは個々の単語を深く理解する必要があります。加えて、それらの単語がより広いテキストの中でどのように相互作用するのかも理解しなければなりません。
言語のバリエーション
世界には多様な言語があり、多くの方言、慣用表現、固有の文法構造が存在します。この 多様性により、NER が複数の言語で一貫した性能を発揮することは難しくなります し、同じ言語内のバリエーションであっても課題になります。 さらに、語順や構文上の違いなどの要因は、モデルがエンティティを正確に識別・分類する能力に影響します。
言語の多様性は、NERモデルにとって非常に重要な要素になり得ます。
データ不足
もう一つの重要な課題はデータ不足です。多くの実世界のアプリケーションでは、専門的または一般的ではないデータ領域を扱う必要がありますが、そのような領域ではアノテーション済み学習データセットが不足しがちです。十分な学習データがない場合、NERモデルは効果的なエンティティ認識に必要なパターンや関係を学習するのに苦労します。
当然ながら、この制約はモデルの性能を妨げる可能性があります。特に、ニッチな分野や新しいトピックに適用する場合に影響が大きくなります。
モデルの汎化
最後に、モデルの汎化も重要です。これは、学習データセットとは異なる 新しい未知のデータに対しても高い性能を発揮する能力 を指します。このレベルの適応性を実現することは特に難しいです。実世界の言語は多様で予測しにくいからです。
そのため、特定のデータセットで訓練されたモデルは、まったく異なる文脈でエンティティを認識できなかったり、正しく分類できなかったりする場合があります。結果として、領域をまたいだスケーラビリティと有用性が制限されます。
まとめ
NERモデルは、テキストの処理と分析の方法を変革し、さまざまな業界に大きな価値を提供しています。AI の進歩とデータ量の増加に支えられて NLP の導入が進むほど、NER の応用可能性はさらに広がります。医療、金融、カスタマーサービスのいずれにおいても、NER は AI ツール群の中で強力な存在です。組織は、非構造化データの可能性を最大限に引き出すことを期待できます。
HDWEBSOFT は AI と ML 開発を専門としており、企業が NER を業務へスムーズに統合できるよう支援します。人工知能と自然言語処理に関する当社の専門知識により、企業は NER の力を効率的に活用できます。競争の激しい現在の環境で一歩先を行くために、この先端技術の活用をぜひお任せください。
