
Ein NER-Modell (Named Entity Recognition) ist ein Eckpfeiler der NLP (Natural Language Processing) und dient der Identifizierung und Klassifizierung von Entitäten in Texten. Angesichts des exponentiellen Wachstums unstrukturierter Daten ist die Extraktion aussagekräftiger Informationen für Unternehmen unerlässlich geworden. Die Fähigkeit, Textdaten zu analysieren und zu organisieren, hat NER in verschiedenen Branchen unverzichtbar gemacht.
In diesem Artikel erklären wir Ihnen anhand eines einfachen Beispiels, was genau Named Entity Recognition ist und welches Konzept dahintersteckt. Darüber hinaus stellen wir Ihnen verschiedene Anwendungsfälle von NER vor und erläutern seine Funktionsweise.
Was ist Named Entity Recognition?
 ist eine Technik der natürlichen Sprachverarbeitung (NLP), die spezifische Entitäten in Texten identifiziert und kategorisiert. Zu diesen Entitäten gehören beispielsweise Personen, Organisationen, Orte, Datumsangaben, Zahlenwerte und vieles mehr.
NER ist das Herzstück dieser Technologie und ermöglicht es Systemen, unstrukturierte Textdaten zu strukturieren, indem sie aussagekräftige Erkenntnisse extrahieren. Das NER-Modell bildet das Rückgrat vieler Anwendungen, wie etwa Chatbots, Stimmungsanalysen und Suchmaschinen. Laut einem aktuellen Bericht wird der globale NLP-Markt voraussichtlich ein Volumen von 156,80 Milliarden US-Dollar erreichen.https://www.statista.com/outlook/tmo/artificial-intelligence/natural-language-processing/worldwideBis 2030 können wir dank des Einsatzes von Tools wie NER eine vielversprechende Zukunft für KI und ML in verschiedenen Bereichen erwarten.
Der Zweck des NER-Modells
Das Hauptziel eines Named Entity Recognition-Modells ist die Umwandlung von Rohdaten in ein strukturiertes Format** für die Analyse. Durch die Kategorisierung wichtiger Informationen hilft es Unternehmen, aus großen Datensätzen verwertbare Erkenntnisse zu gewinnen. Dies ermöglicht effiziente Entscheidungsfindung und unterstützt Anwendungen in Branchen wie dem Gesundheitswesen, dem Finanzwesen und dem Kundenservice.
Das Schlüsselkonzept des NER-Modells

Im Hintergrund nutzt NER mehrere Schlüsselkonzepte und -techniken, um Sprache effektiv zu verstehen und zu verarbeiten. Lassen Sie uns diese Komponenten genauer betrachten.
POS-Tagging
Das Tagging nach Wortarten (Parts of Speech, POS-Tagging) ist einer der grundlegenden Schritte beim Aufbau eines NER-Modells. Dabei wird jedes Wort in einem Satz seiner grammatikalischen Funktion zugeordnet, z. B. Nomen, Verb, Adjektiv oder Adverb. Im Satz „Der Arzt besuchte Paris“ würde das Modell beispielsweise „Arzt“ als Nomen und „besuchte“ als Verb kennzeichnen.
Dieses Tagging ist für NER entscheidend, da es dem Modell hilft, die Rolle jedes Wortes im Satz zu verstehen. Eigennamen bezeichnen häufig Namen, Orte oder Organisationen. In diesem Zusammenhang liefert das POS-Tagging Kontext und ermöglicht dem Modell so genauere Vorhersagen bei der Kategorisierung von Entitäten.
Im Wesentlichen ermöglicht dieser Tagging-Prozess dem Modell, sich auf Wörter zu konzentrieren, die wahrscheinlich Entitäten repräsentieren, und so seine Präzision zu erhöhen.
Korpus
Ein Korpus ist im Wesentlichen eine große Textsammlung, die zum Trainieren des Modells zur Erkennung benannter Entitäten (NER) verwendet wird. Dieser Datensatz ist mit annotierten Beispielen versehen, die beispielsweise Namen, Orte und Daten kennzeichnen. In einem Trainingskorpus für ein NER-Modell würde der Satz „Apple Inc. hat seinen Sitz in Kalifornien“ Apple Inc. als Organisation und Kalifornien als Ort hervorheben.
Die Qualität und Vielfalt des Korpus beeinflussen die Leistung des Modells direkt. Ein umfassender Korpus stellt sicher, dass NER verschiedene Textarten verarbeiten kann, von formellen Geschäftsdokumenten bis hin zu informellen Social-Media-Beiträgen. Indem das Modell Muster aus dem Korpus lernt, kann es sein Verständnis generalisieren und unbekannte Daten effektiv verarbeiten.
Chunking
Als Nächstes betrachten wir das Chunking, auch bekannt als flaches Parsing. Dabei werden Sätze in kleinere, handhabbare Phrasen oder Chunks zerlegt. Beispielsweise könnte der Satz „The quick brown fox jumped over the lazy dog“ in Phrasen wie „The quick brown fox“ und „over the lazy dog“ unterteilt werden.
Im Kontext der Named Entity Recognition (NER) hilft Chunking dabei, Wörter zu gruppieren, um Entitäten zu identifizieren. Dieses Konzept des NER-Modells ist besonders wichtig für Entitäten, die aus mehreren Wörtern bestehen. In solchen Fällen ist das Verständnis der Beziehungen zwischen den Wörtern entscheidend für eine genaue Erkennung.
Word Embeddings
Word Embeddings sind mathematische Repräsentationen von Wörtern in einem mehrdimensionalen Raum. Sie stellen fortgeschrittene Repräsentationen von Wörtern in numerischer Form dar und erfassen deren semantische Bedeutung und Kontextbeziehungen.
In der NER spielen Embeddings wie Word2Vec, GloVe oder solche, die von Transformer-basierten Modellen wie BERT generiert werden, eine entscheidende Rolle. Konkret ermöglichen diese Einbettungen dem Modell, sowohl die wörtliche Bedeutung eines Wortes als auch seine Beziehung zu anderen Wörtern in einem Satz zu verstehen. Diese Fähigkeit ist besonders wichtig, um Entitäten in mehrdeutigen oder komplexen Kontexten zu unterscheiden. Ohne eine solch tiefgehende Analyse liefern oberflächliche Ansätze möglicherweise keine genauen Ergebnisse.
Ein Beispiel für Named Entity Recognition
Betrachten Sie den folgenden Satz zum Testen eines NER-Modells: „Tesla gab bekannt, dass Elon Musk plant, bis Ende 2025 eine neue Fabrik in Austin, Texas, zu eröffnen.“

Das NER-Modell wurde mithilfe des [displaCy Named Entity Visualizer]( auf den Satz angewendet.https://demos.explosion.ai/displacy-ent)._
In diesem Satz:
-
„Tesla“ ist als ORG gekennzeichnet und steht für eine Organisation oder ein Unternehmen.
-
„Elon Musk“ ist als PERSON gekennzeichnet und bezeichnet somit einen Personennamen.
-
„Austin“ und „Texas“ sind als GPE klassifiziert, was für Geopolitische Entität steht und bestimmte Städte oder Regionen identifiziert.
-
„2025“ wird als DATUM erkannt und steht für einen Zeitfaktor.
Wenn Sie solche benannten Entitäten automatisch aus Texten extrahieren und kategorisieren möchten, ist NER die richtige Technik. Sie hilft Computern, die Bedeutung von Texten zu verstehen, indem sie Schlüsselelemente und deren Beziehungen identifiziert.
Wichtige Anwendungsfälle des NER-Modells
Das Named Entity Recognition-Modell (NER) treibt Innovationen in verschiedenen Branchen voran. Durch die Identifizierung und Kategorisierung von Entitäten in unstrukturierten Texten ermöglicht es Unternehmen, Prozesse zu optimieren, Erkenntnisse zu gewinnen und datengestützte Entscheidungen zu treffen. Lassen Sie uns einige der wichtigsten Anwendungen des NER-Modells in verschiedenen Bereichen untersuchen:
Information Retrieval
Eine der Hauptanwendungen von NER ist das Information Retrieval. In einer Zeit, in der täglich riesige Datenmengen generiert werden, ist das Auffinden relevanter Informationen aus unstrukturierten Texten von großer Bedeutung. Insbesondere die Named Entity Recognition (NER) eignet sich hervorragend zum Extrahieren von Entitäten wie Namen, Orten, Daten oder spezifischen Begriffen aus umfangreichen Datensätzen. Dadurch wird es einfacher, relevante Inhalte zu indizieren und zu durchsuchen.

Das NER-Modell ist besonders nützlich, um Informationen aus großen Datenmengen zu extrahieren.
Nehmen wir die Rechtsbranche als Beispiel. Das Named Entity Recognition-Modell kann Fallnummern, Namen von Prozessbeteiligten oder Urteilsdetails aus juristischen Dokumenten extrahieren. Dadurch wird die Fallrecherche beschleunigt. Auch in der Wissenschaft nutzen Forschende es, um wichtige Informationen aus wissenschaftlichen Artikeln oder Datensätzen zu gewinnen und so Zeit und Aufwand zu sparen.
Automatisierte Dateneingabe
Die manuelle Dateneingabe ist nicht nur zeitaufwändig, sondern auch fehleranfällig. Die Technologie automatisiert diesen Prozess, indem sie wichtige Informationen im Text identifiziert und in strukturierte Formate kategorisiert. Insbesondere ist das NER-Modell in Branchen wie dem Gesundheitswesen nützlich, wo eine genaue Datenerfassung für die Patientenversorgung unerlässlich ist.
Beispielsweise kann ein Arzt oder eine Ärztin NER nutzen, um Patientennamen, Krankheitsbilder und verordnete Behandlungen aus klinischen Notizen zu extrahieren. Diese Daten werden dann reibungslos in elektronische Patientenakten (EHRs) übertragen, was den Verwaltungsaufwand reduziert und die Genauigkeit erhöht. Entsprechend dient das Named Entity Recognition (NER)-Modell als Anwendung von KI im Finanzwesen. Konkret kann es die Extraktion von Transaktionsdetails, Kontonummern und Daten aus Rechnungen oder Kontoauszügen automatisieren.
Verbesserung der Stimmungsanalyse
Die Stimmungsanalyse, ein KI-Tool, das häufig im Marketing und Kundenservice eingesetzt wird, dient dazu, die in Texten ausgedrückten Emotionen oder Meinungen zu erfassen. Während die traditionelle Stimmungsanalyse eine Gesamtstimmungsbewertung liefert, verbessert die Integration von NER-Technologie deren Granularität. Das NER-Modell identifiziert spezifische Entitäten im Text, wie z. B. Produktnamen, Erwähnungen von Dienstleistungen oder Wettbewerber. Dadurch können Unternehmen genau feststellen, worüber Kunden sprechen und wie sie darüber denken.
Ein Beispiel: Wenn eine Kundenrezension lautet: „Ich fand die Kamera des neuen iPhone X super, aber die Akkulaufzeit ist enttäuschend“, kann das Modell das iPhone X als Produkt identifizieren. Zusätzlich kann es die Stimmungslage bezüglich Kamera und Akkulaufzeit separat segmentieren. Dieser Detailgrad ist für Unternehmen, die ihr Angebot oder das Kundenerlebnis verbessern möchten, von unschätzbarem Wert.
In Branchen wie dem Einzelhandel und dem Gastgewerbe ist Kundenfeedback entscheidend. Daher liefert das Named Entity Recognition-Modell (NER) wertvolle Erkenntnisse, die zur Verbesserung von Strategien und zur Steigerung der Kundenzufriedenheit beitragen.
Funktionsweise des NER-Modells
Im Kern umfasst NER zwei Hauptschritte:
-
Erkennung von Entitäten im Text.
-
Klassifizierung dieser Entitäten in spezifische Kategorien.
Im Detail:
Entitätserkennung
Der grundlegende Schritt im NER-Modellprozess ist die Entitätserkennung, auch bekannt als Erwähnungserkennung oder Entitäts-Spotting. Dabei werden Textfragmente identifiziert, die relevante Entitäten repräsentieren könnten. Diese Phase ist entscheidend, da sie den Umfang der weiteren Analyse eingrenzt. Dadurch wird sichergestellt, dass nur relevante Textteile in den nächsten Schritt gelangen.

Die Entitätserkennung, der erste Schritt des NER-Modells, dient der Erkennung und Kennzeichnung relevanter Entitäten.
Tokenisierung
Die Tokenisierung ist das Herzstück der Entitätserkennung. Dabei wird ein Satz oder ein Dokument in kleinere Einheiten, sogenannte Tokens, zerlegt. Tokens sind typischerweise Wörter, können aber auch Satzzeichen oder Symbole enthalten. Beispielsweise könnten im Satz „OpenAI created ChatGPT in 2023“ die Tokens „OpenAI“, „created“, „ChatGPT“ und „2023“ sein.
Durch die Segmentierung von Text in überschaubare Einheiten schafft die Tokenisierung die Grundlage für die weitere Verarbeitung. Dadurch kann das NER-Modell spezifische Entitäten aus dem umgebenden Text isolieren.
Merkmalsextraktion
Sobald Tokens identifiziert sind, extrahiert das NER-Modell aussagekräftige Merkmale, um ihr Potenzial als Entitäten zu bestimmen. Dieser Schritt untersucht:
-
Morphologische Merkmale: Diese analysieren Wortstrukturen wie Wortstämme, Präfixe oder Suffixe und helfen so, Varianten wie „run“ und „running“ zu identifizieren.
-
Syntaktische Merkmale: Diese konzentrieren sich auf die Beziehungen zwischen Wörtern in einem Satz. Insbesondere wird ein Nomen, das auf ein Verb folgt, als potenzielle Entität identifiziert.
-
Semantische Merkmale: Diese erfassen die umfassendere Bedeutung eines Wortes in seinem Kontext. So kann das Wort „bank“ je nach Satz eine Bank oder ein Flussufer bezeichnen.
Mithilfe dieser Merkmale stellt NER sicher, dass relevante Entitäten nicht übersehen werden, während irrelevante herausgefiltert werden.
Entitätsklassifizierung
Im nächsten Schritt erfolgt die Entitätsklassifizierung. Hierbei werden erkannte Entitäten basierend auf ihrem Kontext und ihrer Bedeutung vordefinierten Kategorien zugeordnet. Diese Phase ist entscheidend, um Rohdaten in strukturierte Erkenntnisse umzuwandeln.
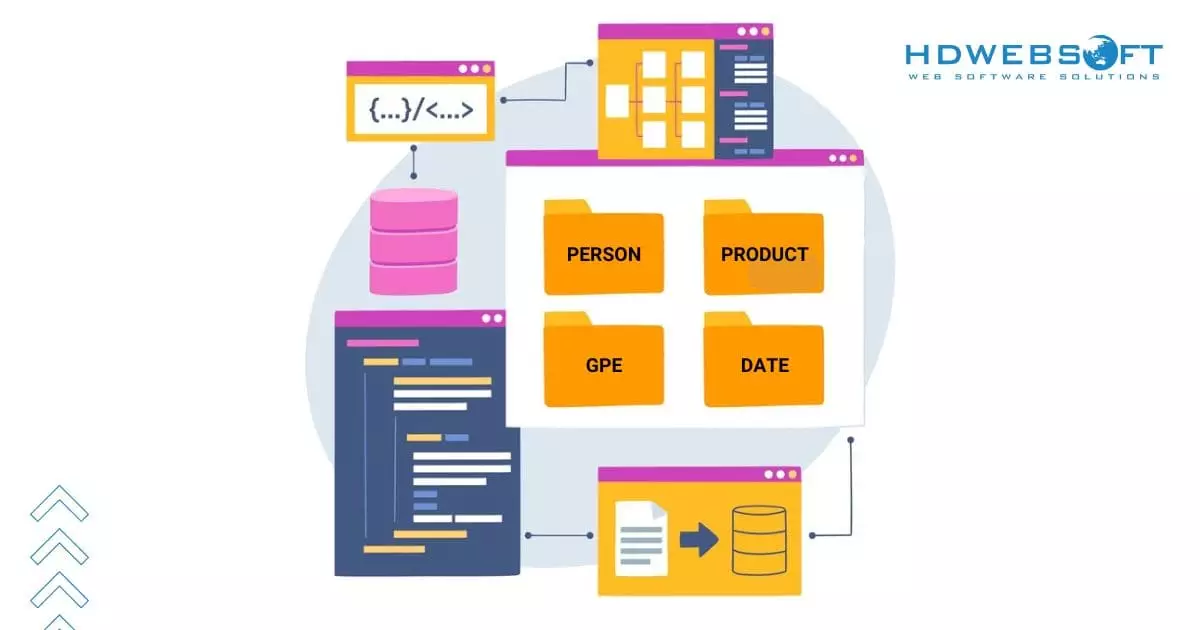
Der nächste Schritt besteht darin, die erkannten Entitäten in vorgegebene Kategorien einzuordnen.
Kontextverständnis
Eine effektive Entitätsklassifizierung im NER-Modell erfordert ein differenziertes Verständnis des Textkontexts. Beispielsweise würde Amazon im Satz „Amazon liefert Waren weltweit“ als Organisation klassifiziert. Im Satz „Der Amazonas-Regenwald ist riesig“ hingegen repräsentiert dasselbe Wort einen Ort.
Um dies zu erreichen, verwendet das Modell eine Kombination aus linguistischer Analyse und maschinellen Lernverfahren, darunter:
-
Regelbasierte Ansätze: Vordefinierte Regeln und Muster, wie z. B. Groß- und Kleinschreibung oder bestimmte Wortstellungen, helfen bei der Kategorisierung von Entitäten.
-
Statistische Modelle: Algorithmen analysieren Muster in annotierten Datensätzen, um Vorhersagen über die Kategorie einer Entität zu treffen.
-
Deep-Learning-Modelle: Fortschrittliche Architekturen wie BERT verwenden Wort-Embeddings, um die tiefere kontextuelle Bedeutung zu erfassen und so den Klassifizierungsprozess zu verfeinern.
Umgang mit Mehrdeutigkeiten
Natürliche Sprache enthält oft Mehrdeutigkeiten, die die Entitätsklassifizierung erschweren. Beispielsweise bezieht sich „Frühling“ in „Der Frühling kommt im März“ auf eine Jahreszeit, während „Spring Technologies hat eine neue App veröffentlicht“ eine Organisation bezeichnet. Die Auflösung solcher Mehrdeutigkeiten erfordert ausgefeilte Modelle, die mit vielfältigen und umfassenden Datensätzen trainiert wurden.
Durch die nahtlose Integration von Entitätserkennung und -klassifizierung wandelt das NER-Modell unstrukturierte Daten in verwertbare Erkenntnisse um. Daher steigert es die Effizienz branchen- und anwendungsübergreifend.
Weiterführende Informationen: Wie wird KI-Textanalyse in der Wirtschaft eingesetzt?
Die Herausforderungen des NER-Modells
Die Named Entity Recognition (NER)-Technologie hat sich als unschätzbar wertvoll erwiesen, ist aber nicht ohne Herausforderungen. Diese Hindernisse entstehen oft durch die Komplexität der menschlichen Sprache und die systembedingten Grenzen der Technologie. Im Folgenden werden einige der drängendsten Herausforderungen des Modells näher betrachtet.
Mehrdeutigkeit
Mehrdeutigkeit ist eine der größten Herausforderungen im Named Entity Recognition (NER). Wörter und Ausdrücke in der natürlichen Sprache haben oft mehrere Bedeutungen, und die Bestimmung der jeweils zutreffenden Bedeutung im Kontext kann schwierig sein.
Daher erschwert dieses Problem die Identifizierung und Kategorisierung von Entitäten, da das Modell die korrekte Bedeutung aus begrenzten Informationen ableiten muss. Darüber hinaus erhöht Mehrdeutigkeit die Fehlerwahrscheinlichkeit, insbesondere in differenzierten oder domänenspezifischen Texten.
Kontextabhängigkeit
Sprache ist stark kontextabhängig, was eine weitere Komplexitätsebene für das NER-Modell darstellt. Die Bedeutung und Kategorisierung von Entitäten hängen oft von den umgebenden Wörtern und Ausdrücken ab.
Denken Sie darüber nach: Ein Begriff, der in einem Kontext eine Entität darstellt, kann in einem anderen Kontext eine völlig andere Bedeutung haben. Diese Abhängigkeit von Kontextinformationen erfordert ein tiefes Verständnis der einzelnen Wörter. Zusätzlich muss das Modell verstehen, wie diese Wörter im Kontext des Gesamttextes interagieren.
Sprachliche Variationen
Die Welt ist von großer Vielfalt an Sprachen geprägt, mit zahlreichen Dialekten, idiomatischen Ausdrücken und einzigartigen grammatikalischen Strukturen. Diese Vielfalt erschwert es der Named Entity Recognition (NER), konsistente Ergebnisse in verschiedenen Sprachen zu erzielen, oder sogar innerhalb derselben Sprache mit Variationen umzugehen. Darüber hinaus können Faktoren wie Wortstellung und syntaktische Unterschiede die Fähigkeit des Modells beeinträchtigen, Entitäten korrekt zu identifizieren und zu klassifizieren.
Die Vielfalt der Sprachen kann für das NER-Modell von entscheidender Bedeutung sein.
Datensparsamkeit
Eine weitere wichtige Herausforderung ist die Datensparsamkeit. Viele Anwendungen in der Praxis erfordern, dass das Modell spezialisierte oder weniger verbreitete Datenbereiche verarbeitet, in denen annotierte Trainingsdatensätze rar sind. Ohne ausreichende Trainingsdaten hat das NER-Modell Schwierigkeiten, die für eine effektive Entitätserkennung notwendigen Muster und Beziehungen zu erlernen.
Diese Einschränkung kann erwartungsgemäß die Leistung beeinträchtigen, insbesondere bei der Anwendung in Nischenbereichen oder aufkommenden Themen.
Modellgeneralisierung
Nicht zuletzt ist die Modellgeneralisierung von Bedeutung. Sie bezeichnet die Fähigkeit, mit neuen, unbekannten Daten, die sich vom Trainingsdatensatz unterscheiden, gute Ergebnisse zu erzielen. Diese Anpassungsfähigkeit zu erreichen ist besonders anspruchsvoll, da die Sprache in realen Szenarien vielfältig und unvorhersehbar ist.
Daher kann es vorkommen, dass ein mit spezifischen Datensätzen trainiertes Modell Entitäten in einem völlig anderen Kontext nicht erkennt oder korrekt klassifiziert. Dies wiederum schränkt seine Skalierbarkeit und Anwendbarkeit in verschiedenen Bereichen ein.
Fazit
Das NER-Modell revolutioniert die Textverarbeitung und -analyse und bietet immensen Mehrwert für verschiedenste Branchen. Mit der zunehmenden Verbreitung von NLP, angetrieben durch Fortschritte in der KI und steigende Datenmengen, sind die Anwendungsmöglichkeiten von NER grenzenlos. Ob im Gesundheitswesen, im Finanzwesen oder im Kundenservice – NER erweist sich als leistungsstarkes Werkzeug im KI-Werkzeugkasten. Unternehmen können das volle Potenzial ihrer unstrukturierten Daten ausschöpfen.
Wir von HDWEBSOFT sind auf KI- und ML-Entwicklung spezialisiert und unterstützen Unternehmen bei der nahtlosen Integration von NER in ihre Abläufe. Unsere Expertise in künstlicher Intelligenz und natürlicher Sprachverarbeitung ermöglicht es Unternehmen, die Vorteile von NER effizient zu nutzen. Lassen Sie uns Ihnen helfen, diese Spitzentechnologie einzusetzen und im heutigen Wettbewerbsumfeld die Nase vorn zu haben.
